TITLE: Studying Program Repositories
AUTHOR: Eugene Wallingford
DATE: October 06, 2010 11:24 AM
DESC:
-----
BODY:
 Last week, Garrett Morris presented an experience
report at the
2010 Haskell Symposium
entitled
Using Hackage to Inform Language Design,
which is also available at
Morris's website.
Hackage is an online repository for the Haskell
programming community. Morris describes how he
and his team studied programs in the Hackage
repository to see how Haskell programmers work
with a type-system concept known as
overlapping instances. The
details of this idea aren't essential to this
entry, but if you'd like to learn more, check
out Section 6.2.3 in this
user guide.)
In Morris's search, he sought answers to three
questions:
Last week, Garrett Morris presented an experience
report at the
2010 Haskell Symposium
entitled
Using Hackage to Inform Language Design,
which is also available at
Morris's website.
Hackage is an online repository for the Haskell
programming community. Morris describes how he
and his team studied programs in the Hackage
repository to see how Haskell programmers work
with a type-system concept known as
overlapping instances. The
details of this idea aren't essential to this
entry, but if you'd like to learn more, check
out Section 6.2.3 in this
user guide.)
In Morris's search, he sought answers to three
questions:
- What proportion of the total code on Hackage
uses overlapping instances?
- In code that uses overlapping instances, how
many instances overlap each other?
- Are there common patterns among the uses of
overlapping instances?
Morris and his team used what they learned from
this study to design the class system for their
new language. They found that their language did
not need to provide the full power of overlapping
instances in order to support what programmers
were really doing. Instead, they developed a new
idea they call "instance chains" that was
sufficient to support a large majority of the uses
of overlapping instances. They are confident that
their design can satisfy programmers because the
design decision reflects actual uses of the concept
in an extensive corpus of programs.
I love this kind of empirical research. One of the
greatest assets the web gives us is access to large
corpora of code: SourceForge and GitHub are examples
large public repositories, and there are an amazing
number of smaller domain-specific repositories such
as Hackage and RubyGems. Why design languages or
programming tools blindly when we can see how real
programmers work through the code they write?
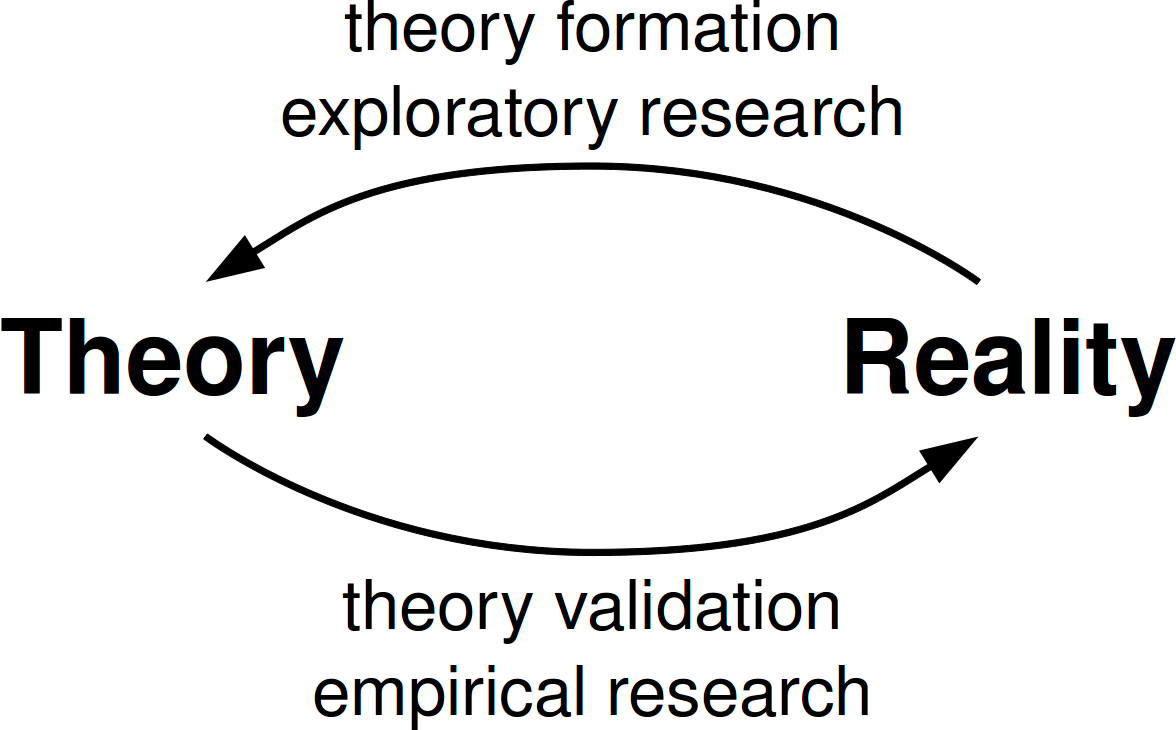
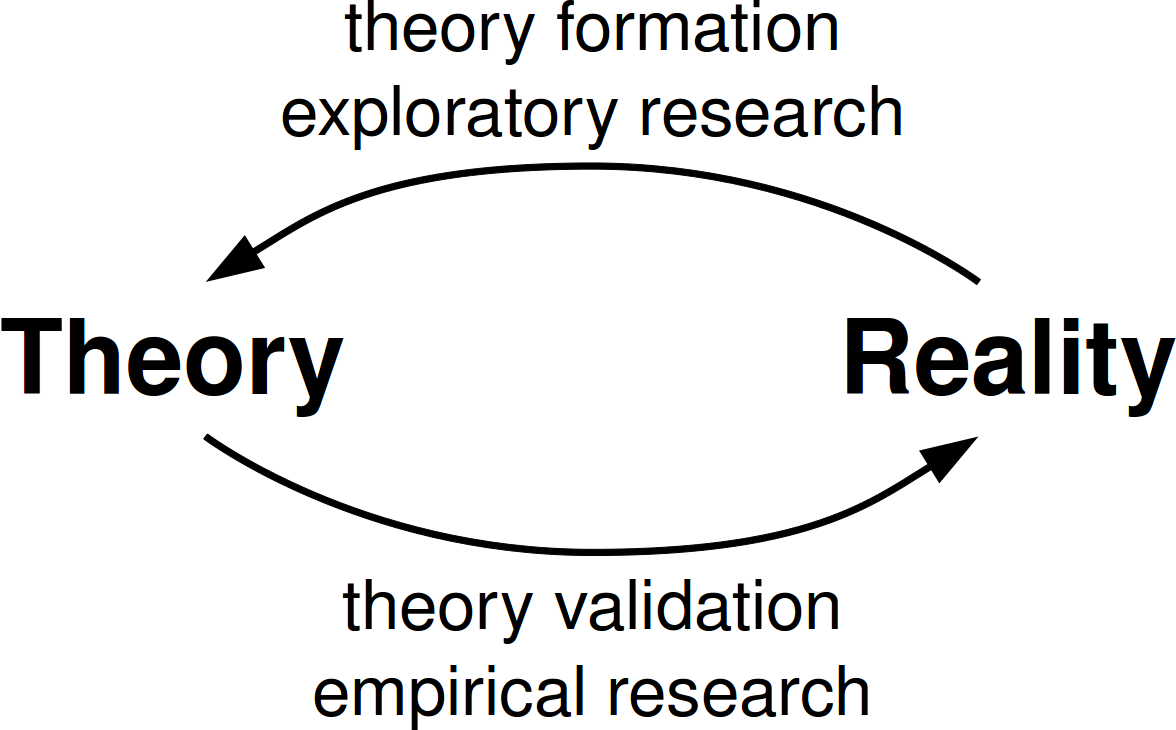
The more general notion of designing languages via
observing behavior, forming theories, and trying
them out is not new. In particular, I recommend
the classic 1981 paper
Design Principles Behind Smalltalk.
Dan Ingalls describes the method by which the
Smalltalk team grew its language and system as
explicitly paralleling the scientific method.
Morris's paper talks about a similar method, only
with the observation phase grounded in an online
corpus of code.
Not everyone in computer science -- or outside CS
-- thinks of this method as science. Just this
weekend Dirk Riehle blogged about the need to
broaden the idea of science in CS.
In particular, he encourages us to include
exploration as a part of our scientific method,
as it provides a valuable way for us to form the
theories that we will test using the sort of
experiments that everyone recognizes as science.
 Unfortunately, too many people in computer science
do not take this broad view. Note that Morris
published his paper as an experience report at a
symposium. He would have a hard time trying to
get an academic conference program committee to
take such a paper in its research track, without
first dressing it up in the garb of "real" research.
As I mentioned in an
earlier blog entry,
one of my grad students, Nate Labelle, did an M.S.
thesis a few years ago based on information gathered
from the study of a large corpus of programs. Nate
was interested in dependencies among open-source
software packages, so he mapped the network of
relationships within several different versions of
Linux and within a few smaller software packages.
This was the raw data he used to analyze the
mathematical properties of the dependencies.
In that project, we trolled repositories looking for
structural information about the code they
contained. Morris's work studied Hackage to learn
about the semantic content of the programs.
While on sabbatical several years ago, I started a
much smaller project of this sort to look for design
patterns in functional programs. That project was
sidetracked by some other questions I ran across,
but I've always wanted to get back to it. I think
there is a lot we could learn about functional
programming in this way that would help us to teach
a new generation of programmers in industry.
-----
Unfortunately, too many people in computer science
do not take this broad view. Note that Morris
published his paper as an experience report at a
symposium. He would have a hard time trying to
get an academic conference program committee to
take such a paper in its research track, without
first dressing it up in the garb of "real" research.
As I mentioned in an
earlier blog entry,
one of my grad students, Nate Labelle, did an M.S.
thesis a few years ago based on information gathered
from the study of a large corpus of programs. Nate
was interested in dependencies among open-source
software packages, so he mapped the network of
relationships within several different versions of
Linux and within a few smaller software packages.
This was the raw data he used to analyze the
mathematical properties of the dependencies.
In that project, we trolled repositories looking for
structural information about the code they
contained. Morris's work studied Hackage to learn
about the semantic content of the programs.
While on sabbatical several years ago, I started a
much smaller project of this sort to look for design
patterns in functional programs. That project was
sidetracked by some other questions I ran across,
but I've always wanted to get back to it. I think
there is a lot we could learn about functional
programming in this way that would help us to teach
a new generation of programmers in industry.
-----