September 29, 2015 4:01 PM
StrangeLoop: Pixie, big-bang, and a Mix Tape
The second day of StrangeLoop was as eventful as the first. Let me share notes on a few more of the talks that I enjoyed.

In the morning, I learned more about Pixie, a small, lightweight version of Lisp at the talk by Timothy Baldridge, its creator. Why another Lisp, especially when its creator already knows and enjoys Clojure? Because he wanted to explore ideas he had come across over the years. Sometimes, there is no better way to do that than to create your own language. This is what programmers do.
Pixie uses Clojure-like syntax and semantics, but it diverges enough from the Clojure spec that he didn't want to be limited by calling it a variant of Clojure. "Lisp" is a generic term these days and doesn't carry as much specific baggage.
Baldridge used RPython and the PyPy tool chain to create Pixie, which has its own virtual machine and its own bytecode format. It also has garbage collection. (Implementors of RPython-based languages don't have to write their own GC; they write hints to a GC generator, which layers the GC code into the generated C of the interpreter.) Pixie also offers strong interoperation with C, which makes it possible to speed up even further hot spots in a program.
For me, the most interesting part of Pixie is its tracing just-in-time compiler. A just-in-time compiler, or "JIT", generates target code at run time, when a specific program provides more information to the translator than just the language grammar. A tracing JIT records frequently executed operations, especially in and around loops, in order to get the information the code generator needs to produce its output. Tracing JITs are an attractive idea for implementing a Lisp, in which programs tend to consist of many small functions. A tracing JIT can dive deep through all those calls and generate small, tight code.

Rather than give a detailed talk about a specific language, David Nolen and Michael Bernstein gave a talk they dubbed "a mix tape to lovers of programming languages". They presented an incomplete and very personal look at the history of programming languages, and at each point on the timeline they offered artists whose songs reflected a similar development in the music world. Most of the music was out of the mainstream, where connoisseurs such as Nolen and Bernstein find and appreciate hidden gems. Some of it sounded odd to a modern ear, and at one point Bernstein gently assured the audience, "It's okay to laugh."
The talk even taught me one bit of programming history that I didn't know before. Apparently, John Backus got his start by trying to make a hi-fi stereo system for listening to music! This got him into radios and electronics, and then into programming computers at the hardware level. Bernstein quoted Backus as saying, "I figured there had to be a better way." This adds a new dimension to something I wrote on the occasion of Backus's passing. Backus eventually found himself writing programs to compute missile trajectories on the IBM 701 mainframe. "Much of my work has come from being lazy," Backus said, so "I started work on a programming system to make it easier to write programs." The result was Fortran.
Nolen and Bernstein introduced me to some great old songs, as well as several new artists. Songs by jazz pianist Cecil Taylor and jazz guitarist Sonny Sharrock made particular impressions on me, and I plan to track down more of their work.
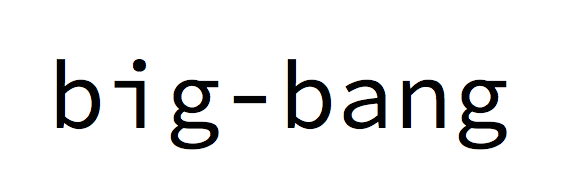
Matthias Felleisen combined history and the details of a specific system in his talk about big-bang, the most recent development in a 20-year journey to find ways to integrate programming with mathematical subjects in a way that helps students learn both topics better. Over that time, he and the PLT team have created a sequence of Racket libraries and languages that enable students to begin with middle-school pre-algebra and progress in smooth steps all the way up to college-level software engineering. He argued near the end of his talk that the progression does not stop there, as extension of big-bang has led to bona fide CS research into network calculus.
All of this programming is done in the functional style. This is an essential constraint if we wish to help students learn and so real math. Felleisen declared boldly "I don't care about programming per se" when it comes to programming in the schools. Even students who never write another program again should have learned something valuable in the content area.
The meat of the talk demonstrated how big-bang makes it possible for students to create interactive, graphical programs using nothing but algebraic expressions. I can't really do justice to Matthias's story or storytelling here, so you should probably watch the video. I can say, though, that the story he tells here meshes neatly with The Racket Way as part of a holistic vision of computing unlike most anything you will find in the computing world. It's impressive both in the scope of its goals and in the scope of the tools it has produced.
More notes on StrangeLoop soon.
~~~~
PHOTO. I took both photos above from my seats in the audience at StrangeLoop. Please pardon my unsteady hand. CC BY-SA.
September 27, 2015 6:56 PM
StrangeLoop is in the Books
 |
The conference came and went far too quickly, with ideas enough for many more days. As always, Alex Miller and his team put on a first-class program with the special touches and the vibe that make me want to come back every year.
Most of the talks are already online. I will be writing up my thoughts on some of the talks that touched me deepest in separate entries over the next few days. For now, let me share notes on a few other talks that I really enjoyed.
Carin Meier talked about her tinkering with the ideas of chemical computing, in which we view molecules and reactions as a form of computation. In her experiments, Meier encoded numbers and operations as molecules, put them in a context in which they could react with one another, and then visualized the results. This sort of computation may seem rather inefficient next to a more direct algorithm, it may give us a way to let programs discover ideas by letting simple concepts wander around and bump into one another. This talk reminded me of AM and Eurisko, AI programs from the late 1970s which always fascinated me. I plan to try Meier's ideas out in code.
Jan Paul Posma gave us a cool look at some Javascript tools for visualizing program execution. His goal is to make it possible to shift from ordinary debugging, which follows something like the scientific method to uncover hidden errors and causes, to "omniscient debugging", in which everything we need to understand how our code runs is present in the system. Posma's code and demos reminded me of Bret Victor's work, such as learnable programming.
Caitie McCaffrey's talk on building scalable, stateful services and Camille Fournier's talk on hope and fear in distributed system design taught me a little about a part of the computing world I don't know much about. Both emphasized the importance of making trade-offs among competing goals and forces. McCaffrey's talk had a more academic feel, with references to techniques such as distributed hash tables with nondeterministic placement, whereas Fournier took a higher-level look at how context drives the balance between scale and fault tolerance. From each talk I took at least one take-home lesson for me and my students:
- McCaffrey asked, "Should you read research papers?" and immediately answered "Yes." A lot of the ideas we need
today appear in the database literature of the '60s, '70s, and '80s. Study!
- Fournier says that people understand asynchrony and changing data better than software designers seem to think. If we take care of the things that matter most to them, such as not charging their credit cards more once, they will understand the other effects of asynchrony as simply one of the costs of living in a world that gives them amazing possibilities.
Fournier did a wonderful job stepping in to give the Saturday keynote address on short notice. She was lively, energetic, and humorous -- just what the large audience needed after a long day of talks and a long night of talking and carousing. Her command of the room was impressive.
More notes soon.
~~~~
PHOTO. One of the plaques on the outside wall of the St. Louis Public Library, just a couple of blocks from the Peabody Opera House and StrangeLoop. Eugene Wallingford, 2015. Available under a CC BY-SA license.
September 24, 2015 9:04 PM
Off to StrangeLoop
 |
StrangeLoop 2015 starts tomorrow, and after a year's hiatus, I'm back. The pre-conference workshops were today, and I wish I could have been here in time for the Future of Programming workshop. Alas, I have a day job and had to teach class before hitting the road. My students knew I was eager to get away and bid me a quick goodbye as soon as we wrapped up our discussion of table-driven parsing. (They may also have been eager to finish up the scanners for their compiler project...)
As always, the conference line-up consists of strong speakers and intriguing talks throughout. Tomorrow, I'm looking forward to talks by Philip Wadler and Gary Bernhardt. Wadler is Wadler, and if anyone can shed new light in 2015 on the 'types versus unit tests' conflagration and make it fun, it's probably Bernhardt.
On Saturday, my attention is honed in on David Nolen's and Michael Bernstein's A History of Programming Languages for 2 Voices. I've been big fans of their respective work for years, swooning on Twitter and reading their blogs and papers, and now I can see them in person. I doubt I'll be able to get close, though; they'll probably be swamped by groupies. Immediately after that talk, Matthias Felleisen is giving a talk on Racket's big-bang, showing how we can use pure functional programming to teach algebra to middle school students and fold the network into the programming language.
Saturday was to begin with a keynote by Kathy Sierra, whom I last saw many years ago at OOPSLA. I'm sad that she won't be able to attend after all, but I know that Camille Fournier's talk about hopelessness and confidence in distributed systems design will be an excellent lead-off talk for the day.
I do plan one change for this StrangeLoop: my laptop will stay in its shoulder bag during all of the talks. I'm going old school, with pen and a notebook in hand. My mind listens differently when I write notes by hand, and I have to be more frugal in the notes I take. I'm also hoping to feel a little less stress. No need to blog in real time. No need to google every paper the speakers mention. No temptation to check email and do a little work. StrangeLoop will have my full attention.
The last time I came to StrangeLoop, I read Raymond Queneau's charming and occasionally disorienting "Exercises in Style", in preparation for Crista Lopes's talk about her exercises in programming style. Neither the book nor talk disappointed. This year, I am reading The Little Prince -- for the first time, if you can believe it. I wonder if any of this year's talks draw their inspiration from Saint-Exupéry? At StrangeLoop, you can never rule that kind of connection out.
September 22, 2015 2:57 PM
"Good Character" as an Instance of Postel's Law
Mike Feathers draws an analogy I'd never thought of before in The Universality of Postel's Law: what we think of as "good character" can be thought of as an application of Postel's Law to ordinary human relations.
Societies often have the notion of 'good character'. We can attempt all sorts of definitions but at its core, isn't good character just having tolerance for the foibles of others and being a person people can count on? Accepting wider variation at input and producing less variation at output? In systems terms that puts more work on the people who have that quality -- they have to have enough control to avoid 'going off' on people when others 'go off on them', but they get the benefit of being someone people want to connect with. I argue that those same dynamics occur in physical systems and software systems that have the Postel property.
These days, most people talk about Postel's Law as a social law, and criticisms of it even in software design refer to it as creating moral hazards for designers. But Postel coined this "principle of robustness" as a way to talk about implementing TCP, and most references I see to it now relate to HTML and web browsers. I think it's pretty cool when a software design principle applies more broadly in the design world, or can even be useful for understanding human behavior far removed from computing. That's the sign of a valuable pattern -- or anti-pattern.
Posted by Eugene Wallingford | Permalink | Categories: Computing, General, Patterns, Software Development
September 19, 2015 11:56 AM
Software Gets Easier to Consume Faster Than It Gets Easier to Make
In What Is the Business of Literature?, Richard Nash tells a story about how the ideas underlying writing, books, and publishing have evolved over the centuries, shaped by the desires of both creators and merchants. One of the key points is that technological innovation has generally had a far greater effect on the ability to consume literature than on the ability to create it.
But books are just one example of this phenomenon. It is, in fact, a pattern:
For the most part, however, the technical and business-model innovations in literature were one-sided, far better at supplying the means to read a book than to write one. ...
... This was by no means unique to books. The world has also become better at allowing people to buy a desk than to make a desk. In fact, from medieval to modern times, it has become easier to buy food than to make it; to buy clothes than to make them; to obtain legal advice than to know the law; to receive medical care than to actually stitch a wound.
One of the neat things about the last twenty years has been the relatively rapid increase in the ability for ordinary people to to write and disseminate creative works. But an imbalance remains.
Over a shorter time scale, this one-sidedness has been true of software as well. The fifty or sixty years of the Software Era have given us seismic changes in the availability, ubiquity, and backgrounding of software. People often overuse the word 'revolution', but these changes really have had an immense effect in how and when almost everyone uses software in their lives.
Yet creating software remains relatively difficult. The evolution of our tools for writing programs hasn't kept pace with the evolution in platforms for using them. Neither has the growth in our knowledge of how make great software.
There is, of course, a movement these days to teach more people how to program and to support other people who want to learn on their own. I think it's wonderful to open doors so that more people have the opportunity to make things. I'm curious to see if the current momentum bears fruit or is merely a fad in a world that goes through fashions faster than we can comprehend them. It's easier still to toss out a fashion that turns out to require a fair bit of work.
Writing software is still a challenge. Our technologies have not changed that fact. But this is also true, as Nash reminds us, of writing books, making furniture, and a host of other creative activities. He also reminds us that there is hope:
What we see again and again in our society is that people do not need to be encouraged to create, only that businesses want methods by which they can minimize the risk of investing in the creation.
The urge to make things is there. Give people the resources they need -- tools, knowledge, and, most of all, time -- and they will create. Maybe one of the new programmers can help us make better tools for making software, or lead us to new knowledge.
Posted by Eugene Wallingford | Permalink | Categories: Computing, General, Patterns, Software Development
September 18, 2015 3:17 PM
Confidence and Small, Clear Code
Net Prophet, aka Scott Turner, is porting the Pain Machine, his college hoops prediction system, from Common Lisp to Python. The new program is getting different values than the old one in one portion of the code, though they don't seem to affect model's overall performance. Which program is right?
I suspect the Python version is probably "more correct" than the Common Lisp version, because this is a matrix-manipulation heavy part of the code, and it is expressed much more succinctly and clearly in Python.
Scott's a darn good programmer and someone with a lot of Lisp experience, so don't go there. This isn't a language testimonial. It's a testament to how programmers' confidence in their code goes up when they can see more clearly that it says what they intended to say. It is easier to trust something we understand. (But don't forget to run some tests, too!)
September 11, 2015 3:55 PM
Search, Abstractions, and Big Epistemological Questions
Andy Soltis is an American grandmaster who writes a monthly column for Chess Life called "Chess to Enjoy". He has also written several good books, both recreational and educational. In his August 2015 column, Soltis talks about a couple of odd ways in which computers interact with humans in the chess world, ways that raise bigger questions about teaching and the nature of knowledge.
As most people know, computer programs -- even commodity programs one can buy at the store -- now play chess better than the best human players. Less than twenty years ago, Deep Blue first defeated world champion Garry Kasparov in a single game. A year later, Deep Blue defeated Kasparov in a closely contested six-game match. By 2005, computers were crushing Top Ten players with regularity. These days, world champion Magnus Larson is no match for his chess computer.
 |
Yet there are still moments where humans shine through. Soltis opens with a story in which two GMs were playing a game the computers thought Black was winning, when suddenly Black resigned. Surprised journalists asked the winner, GM Vassily Ivanchuk, what had happened. It was easy, he said: it only looked like Black was winning. Well beyond the computers' search limits, it was White that had a textbook win.
How could the human players see this? Were they searching deeper than the computers? No. They understood the position at a higher level, using abstractions such as "being in the square" and passed pawns like splitting a King like "pants". (We chessplayers are an odd lot.)
When you can define 'flexibility' in 12 bits,
it will go into the program.
Attempts to program computers to play chess using such abstract ideas did not work all that well. Concepts like king safety and piece activity proved difficult to implement in code, but eventually found their way into the programs. More abstract concepts like "flexibility", "initiative", and "harmony" have proven all but impossible to implement. Chess programs got better -- quickly -- when two things happened: (1) programmers began to focus on search, implementing metrics that could be applied rapidly to millions of positions, and (2) computer chips got much, much faster.
 |
The result is that chess programs can beat us by seeing farther down the tree of possibilities than we do. They make moves that surprise us, puzzle us, and even offend our sense of beauty: "Fischer or Tal would have played this move; it is much more elegant." But they win, easily -- except when they don't. Then we explain why, using ideas that express an understanding of the game that even the best chessplaying computers don't seem to have.
This points out one of the odd ways computers relate to us in the world of chess. Chess computers crush us all, including grandmasters, using moves we wouldn't make and many of us do not understand. But good chessplayers do understand why moves are good or bad, once they figure it out. As Soltis says:
And we can put the explanation in words. This is why chess teaching is changing in the computer age. A good coach has to be a good translator. His students can get their machine to tell them the best move in any position, but they need words to make sense of it.
Teaching computer science at the university is affected by a similar phenomenon. My students can find on the web code samples to solve any problem they have, but they don't always understand them. This problem existed in the age of the book, too, but the web makes available so much material, often undifferentiated and unexplained, so, so quickly.
The inverse of computers making good moves we don't understand brings with it another oddity, one that plays to a different side of our egos. When a chess computer loses -- gasp! -- or fails to understand why a human-selected move is better than the moves it recommends, we explain it using words that make sense of human move. These are, of course, the same words and concepts that fail us most of the time when we are looking for a move to beat the infernal machine. Confirmation bias lives on.
Soltis doesn't stop here, though. He realizes that this strange split raises a deeper question:
Maybe it's one that only philosophers care about, but I'll ask it anyway:
Are concepts like "flexibility" real? Or are they just artificial constructs, created by and suitable only for feeble, carbon-based minds?
(Philosophers are not the only ones who care. I do. But then, the epistemology course I took in grad school remains one of my two favorite courses ever. The second was cognitive psychology.)
 |
We can implement some of our ideas about chess in programs, and those ideas have helped us create machines we can no longer defeat over the board. But maybe some of our concepts are simply be fictions, "just so" stories we tell ourselves when we feel the need to understand something we really don't. I don't think so, the pragmatist in me keeps pushing for better evidence.
Back when I did research in artificial intelligence, I always chafed at the idea of neural networks. They seemed to be a fine model of how our brains worked at the lowest level, but the results they gave did not satisfy me. I couldn't ask them "why?" and receive an answer at the conceptual level at which we humans seem to live. I could not have a conversation with them in words that helped me understand their solutions, or their failures.
Now we live in a world of "deep learning", in which Google Translate can do a dandy job of translating a foreign phrase for me but never tell me why it is right, or explain the subtleties of choosing one word instead of another. Add more data, and it translates even better. But I still want the sort of explanation that Ivanchuk gave about his win or the sort of story Soltis can tell about why a computer program only drew a game because it saddled itself with inflexible pawn structure.
Perhaps we have reached the limits of my rationality. More likely, though, is that we will keep pushing forward, bringing more human concepts and abstractions within the bounds of what programs can represent, do, and say. Researchers like Douglas Hofstadter continue the search, and I'm glad. There are still plenty of important questions to ask about the nature of knowledge, and computer science is right in the middle of asking and answering them.
~~~~
IMAGE 1. The critical position in Ivanchuk-Jobava, Wijk aan Zee 2015, the game to which Soltis refers in his story. Source: Chess Life, August 2015, Page 17.
IMAGE 2. The cover of Andy Soltis's classic Pawn Structure Chess. Source: the book's page at Amazon.com.
IMAGE 3. A bust of Aristotle, who confronted Plato's ideas about the nature of ideals. Source: Classical Wisdom Weekly.
September 03, 2015 3:26 PM
Compilers and the Universal Machine
I saw Eric Normand's The Most Important Idea in Computer Science a few days ago and enjoyed it. I almost always enjoy watching a programmer have fun writing a little interpreter and then share that fun with others.
In class this week, my students and I spent a few minutes playing with T-diagrams to illustrate techniques for porting, bootstrapping, and optimizing compilers, and Normand's post came to mind. So I threw a little purple prose into my classroom comments.
All these examples of building compilers by feeding programs for new compilers into old compilers ultimately depend on a single big idea from the theory of computer science: that a certain kind of machine can simulate anything -- including itself. As a result, this certain kind of machine, the Turing machine, is the very definition of computability. But this big idea also means that, whatever problem we want to solve with information, we can solve it with a program. No additional hardware needed. We can emulate any hardware we might need, new or old, in software.
This is truly one of the most important ideas in computer science. But it's also an idea that changes how we approach problems in nearly every other discipline. Philosophically, it was a monumental achievement in humanity's ongoing quest to understand the universe and our place in it.
In this course, you will learn some of the intricacies of writing programs that simulate and translate other programs. At times, that will be a challenge. When you are deep in the trenches some night, trying to find an elusive error in your code, keep the big idea in mind. Perhaps it will comfort you.
Oh, and I am teaching my compilers course again after a two-year break. Yay!