One way for an agent to decide on action to take is to "think ahead" about the effects of its actions on the world. In order to search for an action in this way, the agent must:
Formulating a problem for search requires:
The result of problem formulation is a problem definition, which consists of:
Formulating a solution for search involves applying one of the search techniques we learned about last time. Those techniques all specialize a generic systematic search algorithm by telling the algorithm which states to favor whenever it has a choice among more than one.
Systematic search can favor...
The other techniques that Ginsberg discusses in Chapter 3 are all variations of the same systematic search them that we developed in our last session.
Notice that the problem formulation is subjective (there are multiple formulations for any problem that satisfy the definitions of our terms), while search is objective (an algorithm can be provided that defines the exact order in which states will be explored).
In doing search, the key is to select a good strategy for biasing the generic algorithm.
BFS and DFS are uninformed search strategies. Uninformed search algorithms explore the states of a problem without knowing anything about the environment. These algorithms work in the same way for every problem, because they do not consider any features that are specific to the problem being solved.
Knowledge is power. Intelligent agents often use knowledge of a domain to make search very efficient -- or even to make search go away! Consider how you play tic-tac-toe, or how an expert chessplayer plays the opening phase of the game. In each case, knowledge of the problem can take a situation that requires search for a novice and replaces it with reflex or table look-up.
How can we use knowledge to improve search?
(Of course, we can also use knowledge before doing the search to formulate the problem better or select the appropriate search algorithm...)
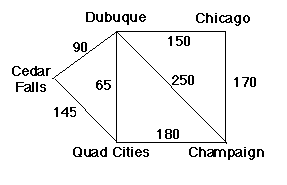
One type of simple extension to search is to use knowledge about path cost. Each operator "costs" something to apply. If my goal is to be in Champaign, Illinois, then there is a cost associated with traveling to Cedar Rapids, and a cost associated with traveling to Waverly.
Consider our simple map from last time...
Knowledge of the cost of applying an operator is problem-specific, because the operators are problem-specific. So any search algorithm that uses these costs in its deliberation is called informed.
In Uniform Cost Search (UCS), we use a strategy that sorts the list in ascending order on path cost. The path cost of a node n is usually called g(n).
This algorithm is a variant of BFS, because it tends to explore states closer to the initial state first. (Applying more operators usually means more total cost.) But UCS's definition of "close" is more practical, because it counts the real cost of a sequence of actions, rather than estimating the cost by the number of actions.
Generally, newly-expanded nodes will enter the queue near the back, with older nodes nearer the front. But a path of low real cost, even if it requires more steps, can leap-frog ahead of a path with fewer operators.
How does UCS stack up against our evaluation criteria from last time?
The problem with UCS is that it is too much like BFS. We aren't using much domain knowledge, just sorting on better information already available.
Where to look next? Well, consider the task of search while the algorithm is running:

It turns out that, if my goal is to be in Champaign, Illinois, then there are two costs associated with traveling to Cedar Rapids, and two costs associated with traveling to Waverly.
UCS uses g(n) to guide its search. g(n) measures the cost expended in getting from the initial state to the current state, the sunk cost of taking the path. (Remember, the agent doing search is thinking ahead at this point, so it hasn't actually expended the cost, just imagined what would happen if it did.)
What about looking at what seems to be a more important measure: what will it cost to get from the current state to the goal?
Greedy search orders the unexplored states in ascending order
of their expected future path cost. Usually, we don't have a way to know
the exact future cost. (In most cases, the knowledge needed to compute
future cost would also compute the solution!) For this reason, greedy
search uses a heuristic function, called h(n), to estimate
future cost.
Hill climbing is usually a very effective search technique, but it falls
victim to several kinds of problem: foothills, plateaus, and ridges. How
can we solve them? (Randomize direction, step size... or jump randomly!)
Greedy search doesn't look like an uninformed method any more, since it
uses information that is very problem-specific. But that
information can be provided as an argument to the search algorithm, so the
general-purpose algorithm still works.
Greedy approaches are often quite efficient, but they generally are not
optimal:
How does greedy search stack up against our evaluation criteria from last
time?
Wrap Up