[Implemented as the Chess Bag Game]
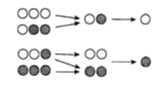
Two players are given a bag containing chess pieces. The pieces are either 'black' or white'. Players take turns removing two pieces at random from the bag. If the pieces are the same color, then the player puts a black piece into the bag. If the pieces are different colors, then the player puts in a white piece.
At the beginning of the game, the players are told how many pieces of each color are in the bag. The "home" player chooses a color. If that is the color of the last piece in the bag, she wins. Otherwise, the "visiting" player wins.
Let's play! Take turns being the home team. Use these "starting positions": 9/8, 5/11, 14/4, 16/3.
"Um, Dr. W., we don't have a bag of chess pieces. Or a can of beans."
Ah, good point. Pretend you do by keeping a tally of the pieces in the bag. Simulate the random draw in some way, say, ...
If nothing else, a course in algorithms should teach us to be resourceful!
Is there any strategy to this game? How can there be, with random choices made? More importantly, how can we tell?
Empirical. Consider some simple cases, and where they lead...
Now consider a more complex case...
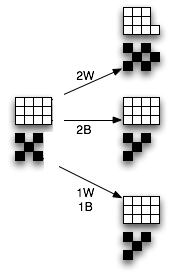
Do you see a pattern?
Analytical. The algorithm for playing the game is as follows:
while number of pieces in bag > 1 do
remove two pieces, chosen randomly
if the pieces are the same color
put in a black piece
else
put in a white piece
What is the invariant?
On each turn, the number of white beans either stays the same or goes down by two. The parity of the white beans never changes! So...
If the initial number of white pieces is odd, then the last piece standing will be white. If it is even, then the last piece standing will be black.
There's your strategy -- and it's O(1)! Seeing patterns can help us find an invariant rule within a problem domain, and invariants really can help us -- not only in analyzing algorithms, but also in designing them. A little knowledge goes a long way.
Suppose that we are given a text comprising characters from a fixed-size alphabet, say the twenty-six letter English alphabet plus a space. We want to compress the text, that is, store it in as few bits as possible.
Unfortunately, standard encodings such as ASCII use the same number of bits for each character, even though some characters occur much more or less frequently than others. For example, in many large English texts, the four most common letters are e, t, a, and o. They occur much more frequently than the letters z and q.
One possible solution seems straightforward: Use shorter bit strings to represent more common characters, and longer bit strings for less common characters. We might assign 0 to e, 1 to t, 00 to a, and 01 to o. Letters such as z and q could be given longer strings, such as 00000 and 00001.
This creates a new challenge. We need to be able to tell where one character's bit string ends and where the next character's bit string begins in a compressed text.
Suppose that an encoded document starts with 011001. Is that an e followed by two ts, or an o followed by a t?
We can make our preferential bit-string solution handle this problems if we select a set of bit strings in which no string is a prefix of another!
We could instead assign 00 to e, 01 to t, 10 to a, and 110 to o. In this code, an e followed by two ts would be encoded as 000101, and an o followed by a t would be encoded as 11001. In each case, there is only one way to decode the compressed text.
|
An Inspiration. Consider the mobile at the right. It consists of several sticks of different lengths. Some of the sticks link to other stick assemblies, and others connect to objects of different weights and sizes. Designed well, a mobile has a pleasing balance.
Notice that each object has a unique "address" in the mobile, depending on whether we go left or right at a junction. Perhaps we can find a way to balance "heavy" es and ts, which occur frequently in our text, with "lighter" zs and qs, which occur rarely? Then each could be given a unique address.
An Implementation. Design a tree whose leaves are the characters of the alphabet, with more common characters appearing closer to the root. Label left and right branches consistently through the tree. Encode each character by its path from the root. To minimize the number of total bits, keep the tree as shallow as possible.
Consider this tree:
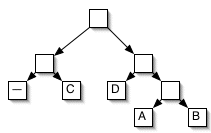
If we label left branches 0 and right branches 1, then we create this code:
_ = 00
C = 01
D = 10
A = 110
B = 111
Notice that no character's code is a prefix of any other's. This means that we can unambiguously decode any encoded text.
Now, how do we know if this is a reasonable coding? That depends on the relative frequencies of the characters in texts. This tree could be the best tree, given the right character distribution. It could also be horribly inefficient.
Suppose that the characters in our texts appear with these probabilities:
_ = 0.15
A = 0.35
B = 0.10
C = 0.20
D = 0.20
At first glance, this doesn't look good. The space is the least common character in the text, but our code uses one of the shortest bit strings for it. A, by far the most common character, has one of the longest.
How can we know for sure how good or bad this coding is? One way is compute the weighted sum of the characters, which gives the average number of bits used per character by the code:
0.35 * 3
0.20 * 2
0.20 * 2
0.15 * 2
+ 0.10 * 3
----------
2.45
Surely we can do better, if we move the more frequent characters closer to the root of the tree. We could naively follow the character frequencies to generate this tree:
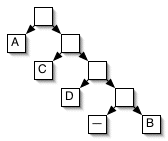
This tree gives us a different coding:
_ = 1110
A = 0
B = 1111
C = 10
D = 110
(We could even make B = 11110!)
Is this tree better than the first? Again, let's compute the weighted sum of the characters:
0.35 * 1
0.20 * 2
0.20 * 3
0.15 * 4
+ 0.10 * 4
----------
2.45
Tree 2 does no better than Tree 1! Though it follows the preference rule, it is too deep. A tree can be deeper than necessary, and when it is, it gives a suboptimal code, too.
We now know how the encoding idea works, and that we need to be careful about how we implement the idea. How do we build a tree that minimizes the size of our compressed texts, one that uses the minimum number of bits possible?
Greed!
Huffman's algorithm grows the tree one node at a time until it contains all of the characters in the alphabet. It selects nodes greedily, pushing subtrees with minimal weights deeper in the tree at each step.
for each character i in the alphabet
create a tree ti consisting of the single node
i labeled with i's frequency in the text
until the tree is connected
select the trees ti and tj
that have the smallest frequencies on their roots
make them the left and right children of a new tree
tnew whose root is the node ij with a label
equal to the sum of the labels of its children
[ ... trace the algorithm using the above frequency distribution ... ]
The resulting tree is:
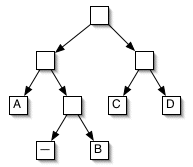
If we label left branches 0 and right branches 1, then we have this code:
_ = 010
A = 00
B = 011
C = 10
D = 11
How many bits per character does this tree require?
0.35 * 2
0.20 * 2
0.20 * 2
0.15 * 3
+ 0.10 * 3
----------
2.25
The Huffman coding requires only 2.25 bits per character. For a text of 1000 characters, it will use 200 fewer bits than the first two trees. That is, for an average text, one whose character distribution matches the frequencies we used to build the tree. If a text has a different frequency distribution, then one or both of the first two trees might do better.
Huffman proved that his coding mechanism generates the minimal average code, so we know that 2.25 is optimal.
This algorithm requires that we know the frequency of each character in the text to be encoded, or for the language as a whole. If we are given a new text to encode, then we can make a first pass through the text to compute the frequencies, build the Huffman code, and then make a second pass to encode the text. (The upfront cost of the first pass can be traded for run-time complexity by constructing the tree dynamically as the text is read on its first pass.)
Huffman's idea has applications to other problems, too. It can be used to create optimal decision trees for any decision procedure. It can also provide a lightweight encryption mechanism. If we do not care to minimize the size of the coded text, then we can use any one of many different trees, each having different shapes and thus different codes, which would make decoding the text practically impossible.
Did you I mention that Huffman designed this algorithm for a homework problem? Actually, it was for a final exam problem. Still, amazing!
[ ... Some closing thoughts on complexity we cannot avoid ... ]
The mathematical and algorithmic side of AI lies in taming such complexity.
I drew many of the games and puzzles I used in this course from the papers of David Ginat, published in places such as inroads and the proceedings of the SIGCSE Technical Symposium. Ginat has some very cool exercises for loosening up our minds, finding invariants, and designing solutions. If you'd like to see more, let me know.
If I offered to grant you one wish to change this course -- to add an algorithm or a class of algorithms, to focus on some content area, ... -- what would you wish for?