October 31, 2011 3:47 PM
"A Pretty Good Lisp"
I occasionally read or hear someone say, "X is a pretty good Lisp", where X is a programming language. Usually, it's a newish language that is more powerful than the languages many of us learned in school. For a good example, see Why Ruby is an acceptable LISP. A more recent article, Ruby is beautiful (but I'm moving to Python) doesn't go quite that far. It says only "almost":
Ruby does not revel in structures or minutiae. It is flexible. And powerful. It really almost is a Lisp.
First, let me say that I like both of these posts. They tell us about how we can do functional programming in Ruby, especially through its support for higher-order functions. As a result, I have found both posts to be useful reading for students. And, of course, I love Ruby, and like Python well enough.
But that's not all there is to Lisp. It's probably not even the most important thing.
Kenny Tilton tells a story about John McCarthy's one-question rebuttal to such claims at the very end of his testimonial on adopting Lisp, Ooh! Ooh! My turn! Why Lisp?:
... [McCarthy] simply asked if Python could gracefully manipulate Python code as data.
"No, John, it can't," said Peter [Norvig] and nothing more...
That's the key: data == program. It really is the Big Idea that sets Lisp apart from the other programming languages we use. I've never been a 100% full-time Lisper, and as a result I don't think I fully appreciate the full power to which Lisp programmers put this language feature. But I've programmed enough with and without macros to be able to glimpse what they see in the ability to gracefully manipulate their code -- all code -- as data.
In the "acceptable Lisp" article linked above, Kidd does address this shortcoming and says that "Ruby gives you about 80% of what you want from macros". Ruby's rather diverse syntax lets us create readable DSLs such as Treetop and Rake, which is one of the big wins that Lisp and Scheme macros give us. In this sense, Ruby code can feel generative, much as macros do.
Unfortunately, Ruby, Python, and other "pretty good Lisps" miss out on the other side of the code-as-data equation, the side McCarthy drew out in his question: manipulation. Ruby syntax is too irregular to generate "by hand" or to read and manipulate gracefully. We can fake it, of course, but to a Lisp programmer it always feels fake.
I think what most people mean when they say a language is a pretty good Lisp is that it can be used as a pretty good functional programming language. But Lisp is not only an FP language. Many would claim it is not even primarily a functional programming language.
I love Ruby. But it's not a pretty good Lisp. It is a fine programming languages, perhaps my favorite these days, with strengths that take it beyond the system programming languages that most of us cut our teeth on. Among those strengths are excellent support for a functional programming style. It also has its weaknesses, like every other programming language.
Neither is Python a pretty good Lisp. Nor is most anything else, for that matter. That's okay.
All I ask is this: When you are reading articles like the ones linked above, don't dismiss every comment you see that says, "No, it's not, and here's why" as the ranting of a smug Lisp weenie. It may be a rant, and it may be written by a smug Lisp weenie. But it may instead be written by a perfectly sane programmer who is trying to teach you that there is more to Lisp than higher-order functions, and that the more you've missed is a whole lot more. We can learn from some of those comments, and think about how to make our programming languages even better.
October 27, 2011 6:44 PM
A Perfect Place to Cultivate an Obsession
And I urge you to please notice when you are happy,
and exclaim or murmur or think at some point,
"If this isn't nice, I don't know what is."
-- Kurt Vonnegut, Jr.
I spent the entire day teaching and preparing to teach, including writing some very satisfying code. It was a way to spend a birthday.
With so much attention devoted to watching my students learn, I found myself thinking consciously about my teaching and also about some learning I have been doing lately, including remembering how to write idiomatic Ruby. Many of my students really want to be able to write solid, idiomatic Scheme programs to process little languages. I see them struggle with the gap between their desire and their ability. It brought to mind something poet Mary Jo Bang said in recent interview about her long effort to become a good writer:
For a long time the desire to write and knowing how to write well remained two separate things. I recognized good writing when I saw it but I didn't know how to create it.
I do all I can to give students examples of good programs from which they can learn, and also to help them with the process of good programming. In the end, the only way to close the gap is to write a lot of code. Writing deliberately and reflectively can shorten the path.
Bang sees the same in her students:
Industriousness can compensate for a lot. And industry plus imagination is a very promising combination.
Hard work is the one variable we all control while learning something new. Some of us are blessed with more natural capacity to imagine, but I think we can stretch our imaginations with practice. Some CS students think that they are learning to "engineer" software, a cold, calculating process. But imagination plays a huge role in understanding difficult problems, abstract problems.
Together, industry and time eventually close the gap between desire and ability:
And I saw how, if you steadily worked at something, what you don't know gradually erodes and what you do know slowly grows and at some point you've gained a degree of mastery. What you know becomes what you are. You know photography and you are a photographer. You know writing and you are a writer.
... You know programming, and you are a programmer.
Erosion and growth can be slow processes. As time passes, we sometimes find our learning accelerates, a sort of negative splits for mental exercise.
We work hardest when we are passionate about what we do. It's hard for homework assigned in school to arouse passion, but many of us professors do what we can. The best way to have passion is to pick the thing you want to do. Many of my best students have had a passion for something and then found ways to focus their energies on assigned work in the interest of learning the skills and gaining the experience they need to fulfill their passion.
One last passage from Bang captures perfectly for me what educators should strive to make "school":
It was the perfect place to cultivate an obsession that has lasted until the present.
As a teacher, I see a large gap between my desire to create the perfect place to cultivate an obsession and my ability to deliver. For, now the desire and the ability remain two separate things. I recognize good learning experiences when I see them, and occasionally I stumble into creating one, but I don't yet know how to create them reliably.
Hard work and imagination... I'll keep at it.
If this isn't nice, I don't know what is.
October 25, 2011 3:53 PM
On the Passing of John McCarthy

It's been a tough couple of weeks for the computer science community. First we lost Steve Jobs, then Dennis Ritchie. Now word comes that John McCarthy, the creator of Lisp, died late Sunday night at the age of 84. I'm teaching Programming Languages this semester based on the idea of implementing small language interpreters, and we are using Scheme. McCarthy's ideas and language are at the heart of what my students and I are doing every day.
Scheme is a Lisp, so McCarthy is its grandfather. Lisp is different from just about every other programming language. It's not just the parentheses, which are only syntax. In Lisp and Scheme, programs and data are the same. To be more specific, the representation of a Lisp program is the the same representation used to represent Lisp data. The equivalence of data and program is one of the truly Big Ideas of computer science, one which I wrote about in Basic Concepts: The Unity of Data and Program. This idea is crucial to many areas of computer science, even ones in which programmers do not take direct advantage of it through their programming language.
We also owe McCarthy for the idea that we can write a language interpreter in the language being interpreted. Actually, McCarthy did more: he stated the features of Lisp in terms of the language features themselves. Such a program defines the language in which the program is written. This is the idea of meta-circular interpreter, in which two procedures:
- a procedure that evaluates an expression, and
- a procedure that applies a procedure to its arguments
Last week, the CS world lost Dennis Ritchie, the creator of the C programming language. By all accounts I've read and heard, McCarthy and Ritchie were very different kinds of people. Ritchie was an engineer through and through, while McCarthy was an academic's academic. So, too, are the languages they created very different. Yet they are without question the two most influential programming languages ever created. One taught us about simplicity and made programming across multiple platforms practical and efficient; the other taught us about simplicity made programming a matter of expressiveness and concision.
Though McCarthy created Lisp, he did not implement the first Lisp interpreter. As Paul Graham relates in Revenge of the Nerds, McCarthy first developed Lisp as a theoretical exercise, an attempt to create an alternative to the Turing Machine. Steve Russell, one of McCarthy's grad students, suggested that he could implement the theory in an IBM 704 machine language program. McCarthy laughed and told him, "You're confusing theory with practice..." Russell did it any way. (Thanks to Russell and the IBM 704, we also have car and cdr!) McCarthy and Russell soon discovered that Lisp was more powerful than the language they had planned to build after their theoretical exercise, and the history of computing was forever changed.
If you'd like, take a look at my Scheme implementation of John McCarthy's Lisp written in Lisp. It is remarkable how much can be built out of so little. Alan Kay has often compared this interpreter to Maxwell's equations in physics. To me, its parts usually feel like the basic particles out of which all matter is built. Out of these few primitives, all programs are built.
I first learned of McCarthy not from Lisp but from my first love, AI. McCarthy coined the term "Artificial Intelligence" when organizing (along with Minsky, Rochester, and Shannon) the 1956 Dartmouth conference that gave birth to the field. I studied McCarthy's work in AI using the language he had created. To me, he was a giant of AI long before I recognized that he was giant of programming languages, too. Like many pioneers of our field, he laid the groundwork in many subdisciplines. They had no choice; they had to build their work out of ideas using only the rawest materials. McCarthy is even credited with the first public descriptions of time-sharing systems and what we now call cloud computing. (For McCarthy's 1970-era predictions about home computers and the cloud, see his The Home Information Terminal, reprinted in 2000.)
Our discipline has lost a giant.
October 24, 2011 7:38 PM
Simple/Complex Versus Easy/Hard
A few years ago, I heard a deacon give a rather compelling talk to a group of college students on campus. When confronted with a recommended way to live or act, students will often say that living or acting that way is hard. These same students are frustrated with the people who recommend that way of living or acting, because the recommenders -- often their parents or teachers -- act as if it is easy to live or act that way. The deacon told the students that their parents and teachers don't think it is easy, but they might well think it is simple.
How can this be? The students were confounding "simple" and "easy". A lot of times, life is simple, because we know what we should do. But that does not make life easy, because doing a simple thing may be quite difficult.
This made an impression on me, because I recognized that conflict in my own life. Often, I know just what to do. That part is simple. Yet I don't really want to do it. To do it requires sacrifice or pain, at least in the short term. To do it means not doing something else, and I am not ready or willing to forego that something. That part is difficult.
Switch the verb from "do" to "be", and the conflict becomes even harder to reconcile. I may know what I want to be. However, the gap between who I am and who I want to be may be quite large. Do I really want to do what it takes to get there? There may be a lot of steps to take which individually are difficult. The knowing is simple, but the doing is hard.
This gap surely faces college students, too, whether it means wanting to get better grades, wanting to live a healthier life, or wanting to reach a specific ambitious goal.
When I heard the deacon's story, I immediately thought of some of my friends, who like very much the idea of being a "writer" or a "programmer", but they don't really want to do the hard work that is writing or programming. Too much work, too much disappointment. I thought of myself, too. We all face this conflict in all aspects of life, not just as it relates to personal choices and values. I see it in my teaching and learning. I see it in building software.
I thought of this old story today when I watched Rich Hickey's talk from StrangeLoop 2011, Simple Made Easy. I had put off watching this for a few days, after tiring of a big fuss that blew up a few weeks ago over Hickey's purported views about agile software development techniques. I knew, though, that the dust-up was about more than just Hickey's talk, and several of my friends recommended it strongly. So today I watched. I'm glad I did; it is a good talk. I recommend it to you!
Based only on what I heard in this talk, I would guess that Hickey misunderstands the key ideas behind XP's practices of test-driven development and refactoring. But this could well be a product of how some agilistas talk about them. Proponents of agile and XP need to be careful not to imply that tests and refactoring make change or any other part of software development easy. They don't. The programmer still has to understand the domain and be able to think deeply about the code.
Fortunately, I don't base what I think about XP practices on what other people think, even if they are people I admire for other reasons. And if you can skip or ignore any references Hickey makes to "tests as guard rails" or to statements that imply refactoring is debugging, I think you will find this really is a very good talk.
Hickey's important point is that simple/complex and easy/hard are different dimensions. Simplicity should be our goal when writing code, not complexity. Doing something that is hard should be our goal when it makes us better, especially when it makes us better able to create simplicity.
Simplicity and complexity are about the interconnectedness of a system. In this dimension, we can imagine objective measures. Ease and difficulty are about what is most readily at hand, what is most familiar. Defined as they are in terms of a person's experience or environment, this dimension is almost entirely subjective.
And that is good because, as Hickey says a couple of times in the talk, "You can solve the familiarity problem for yourself." We are not limited to our previous experience or our current environment; we can take on a difficult challenge and grow.

Alan Kay often talks about how it is worth learning to play a musical instrument, even though playing is difficult, at least at the start. Without that skill, we are limited in our ability to "make music" to turning on the radio or firing up YouTube. With it, you are able make music. Likewise riding a bicycle versus walking, or learning to fly an airplane versus learning to drive a car. None of these skills is necessarily difficult once we learn them, and they enable new kinds of behaviors that can be simple or complex in their own right.
One of the things I try to help my students see is the value in learning a new, seemingly more difficult language: it empowers us to think new and different thoughts. Likewise making the move from imperative procedural style to OOP or to functional programming. Doing so stretches us. We think and program differently afterward. A bonus is that something that seemed difficult before is now less daunting. We are able to work more effectively in a bigger world.
In retrospect, what Hickey says about simplicity and complexity is actually quite compatible with the key principles of XP and other agile methods. Writing tests is a part of how we create systems that are as simple as we can in the local neighborhood of a new feature. Tests can also help us to recognize complexity as it seeps into our program, though they are not enough by themselves to help us see complexity. Refactoring is an essential part of how we eliminate complexity by improving design globally. Refactoring in the presence of unit tests does not make programming easy. It doesn't replace thinking about design; indeed, it is thinking about design. Unit tests and refactoring do help us to grapple with complexity in our code.
Also in retrospect, I gotta make sure I get down to St. Louis for StrangeLoop 2012. I missed the energy this year.
Posted by Eugene Wallingford | Permalink | Categories: Computing, Software Development, Teaching and Learning
October 19, 2011 1:37 PM
A Programming Digression: Benford's Law and Factorials
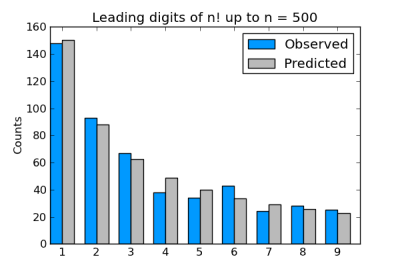
This morning, John Cook posted a blog entry on the leading digits of factorials and how, despite what might be our intuition, they follow Benford's Law. He whipped up some Python code and showed the results of his run for factorials up to 500. I have linked to his graphic at the right.
As I am , I decided to whip up a quick Scheme version of Cook's experiment. He mentioned some implementation issues involving the sizes of integers and floating-point numbers in Python, and I wondered how well Scheme would fare.
For my first attempt, I did the simplest thing that would possibly work. I already had a tail-recursive factorial function and so wrote a procedure that would call it n times and record the first digit of each:
(define benford-factorials
(lambda (n)
(let ((counts (make-vector 10 0)))
(letrec ((foreach
(lambda (n)
(if (zero? n)
counts
(let ((lead-digit (first-digit (factorial n))))
(vector-set! counts lead-digit
(+ 1 (vector-ref counts lead-digit)))
(foreach (- n 1)))))))
(foreach n)))))
This gets the answers for us:
> (benford-factorials 500)
#(0 148 93 67 38 34 43 24 28 25)
Of course, it is wildly inefficient. My naive implementation computes and acts on each factorial independently, which means that it recomputes (n-1)!, (n-2)!, ... for each value less than n. As a result, benford-factorials becomes unnecessarily sluggish for even relatively small values of n. How can I do better?
I decided to create a new factorial function, one that caches the smaller factorials it creates on the way to n!. I call it all-factorials-up-to:
(define all-factorials-up-to
(lambda (n)
(letrec ((aps (lambda (i acc)
(if (> i n)
acc
(aps (+ i 1)
(cons (* i (car acc)) acc))))))
(aps 2 '(1)))))
Now, benford-factorials can use a more functional approach: map first-digit over the list of factorials, and then map a count incrementer over the list of first digits.
(define benford-factorials
(lambda (n)
(let ((counts (make-vector 10 0))
(first-digits (map first-digit
(all-factorials-up-to n))))
(map (lambda (digit)
(vector-set! counts digit
(+ 1 (vector-ref counts digit))))
first-digits)
counts)))
(We can, of course, do without the temporary variable first-digit by dropping the first map right into the second. I often create an explaining temporary variable such as this one to make my code easier for me to write and read.)
How does this one perform? It gets the right answers and runs more comfortably on larger n:
> (benford-factorials 500)
#(0 148 93 67 38 34 43 24 28 25)
> (benford-factorials 1000)
#(0 293 176 124 102 69 87 51 51 47)
> (benford-factorials 2000)
#(0 591 335 250 204 161 156 107 102 94)
> (benford-factorials 3000)
#(0 901 515 361 301 244 233 163 147 135)
> (benford-factorials 4000)
#(0 1192 707 482 389 311 316 227 201 175)
> (benford-factorials 5000)
#(0 1491 892 605 477 396 387 282 255 215)
This procedure begins to be sluggish for n ≥ 3000 on my iMac.
Cook's graph shows how closely the predictions of Benford's Law fit for factorials up to 500. How well do the actual counts match the predicted values for the larger sets of factorials? Here is a comparison for n = 3000, 4000, and 5000:
n = 3000
digit 1 2 3 4 5 6 7 8 9
actual 901 515 361 301 244 233 163 147 135
predicted 903 528 375 291 238 201 174 153 137
n = 4000
digit 1 2 3 4 5 6 7 8 9
actual 1192 707 482 389 311 316 227 201 175
predicted 1204 704 500 388 317 268 232 205 183
n = 5000
digit 1 2 3 4 5 6 7 8 9
actual 1491 892 605 477 396 387 282 255 215
predicted 1505 880 625 485 396 335 290 256 229
That looks pretty close to the naked eye. I've always found Benford's Law to be almost magic, even though mathematicians can give a reasonable account of why it holds. Seeing it work so well with something seemingly as arbitrary as factorials only reinforces my sense of wonder.
If you would like play with these ideas, feel free to start with my Scheme code. It has everything you need to replicate my results above. If you improve on my code or take it farther, please let me know!
October 17, 2011 4:46 PM
Computational Thinking Everywhere: Experiments in Education
I recently ran across Why Education Startups Do Not Succeed, based on the author's experience working as an entrepreneur in the education sector. He admits upfront that he isn't offering objective data to support his conclusions, so we should take them with a grain of salt. Still, I found his ideas interesting. Here is the take-home point in sentences:
Most entrepreneurs in education build the wrong type of business, because entrepreneurs think of education as a quality problem. The average person thinks of it as a cost problem.
That disconnect creates a disconnect between the expectations of sellers and buyers, which ends up hurting, even killing, most education start-ups.
The old AI guy in me latched on to this paragraph:
Interestingly, in the US, the people who are most willing to try new things are the poor and uneducated because they have a similar incentive structure to a person in rural India. Their default state is "screwed." If a poor person doesn't do something dramatic, they are going to stay screwed. Many parents and teachers in these communities understand this. So the communities are often willing to try new, experimental things -- online education, charter schools, longer school days, no summer vacation, co-op programs -- even if they may not work. Why? Because their students default state is "screwed", and they need something dramatically better. Doing something significantly higher quality is the only way to overcome the inertia of already being screwed. The affordable, but poor quality approaches just aren't good enough. These communities are on the hunt for dramatically better approaches and willing to try new things.

I've seen other discussions of the economic behavior of people in the lowest socioeconomic categories that fit this model. Among them were the consumption of lottery tickets in lieu of saving, and more generally the trade-off between savings and consumption. If a small improvement won't help a people much, then it seems they are more likely willing to gamble on big improvements or to simply enjoy short-term rewards of spending.
This mindset immediately brought to mind the AI search technique known as hill climbing. When you know you are on a local maximum that is significantly lower than the global maximum, you are willing to take big steps in search of a better hill to climb, even if that weakens your position in the short-term. Baby steps won't get you there.
This is a small example of unexpected computational thinking in the real world. Psychologically, it seems, that we are often hill climbers.
October 13, 2011 3:10 PM
Learning and New Kinds of Problems
I recently passed this classic by Reg Braithwaite to a grad student who is reading in the areas of functional programming and Ruby. I love how Braithwaite prefaces the technical content of the entry with an exhortation to learners:
... to obtain the deepest benefit from learning a new language, you must learn to think in the new language, not just learn to translate your favourite programming language syntax and idioms into it.
The more different the thing you are learning from what you already know, the more important this advice. You are already good at solving the problems your current languages solve well!
And worse, when a new tool is applied to a problem you think you know well, you will probably dismiss the things the new tool does well. Look at how many people dismiss brevity of code. Note that all of the people ignore the statistics about the constant ratio between bugs and lines of code use verbose languages. Look at how many people dismiss continuation-based servers as a design approach. Note that all of them use programming languages bereft of control flow abstractions.
This is great advice for people trying to learn functional programming, which is all the rage these days. Many people come to a language like Scheme, find it lacking for the problems they have been solving in Python, C, and Java, and assume something is wrong with Scheme, or with functional programming more generally. It's easy to forget that the languages you know and the problems you solve are usually connected in a variety of ways, not the least of which for university students is that we teach them to solve problems most easily solved by the languages we teach them!
If you keep working on the problems your current language solves well, then you miss out on the strengths of something different. You need to stretch not only your skill set but also your imagination.
If you buy this argument, schedule some time to work through Braithwaite's derivation of the Y combinator in Ruby. It will, as my daughter likes to say, make your brain hurt. That's a good thing. Just like with physical exercise, sometimes we need to stretch our minds, and make them hurt a bit, on the way to making them stronger.
October 12, 2011 12:31 PM
Programming for Everyone -- Really?
TL;DR version: Yes.
Yesterday, I retweeted a message that is a common theme here:
Teaching students how to operate software, but not produce software, is like teaching kids to read & not write. (via @KevlinHenney)
It got a lot more action than my usual fare, both retweets and replies. Who knew? One of the common responses questioned the analogy by making another, usually of this sort:
Yeah, that would be like teaching kids how to drive a car, but not build a car. Oh, wait...
This is a sounds like a reasonable comparison. A car is a tool. A computer is a tool. We use tools to perform tasks we value. We do not always want to make our own tools.
But this analogy misses out on the most important feature of computation. People don't make many things with their cars. People make things with a computer.
When people speak of "using a computer", they usually mean using software that runs on a computer: a web browser, a word processor, a spreadsheet program. And people use many of these tools to make things.
As soon as we move into the realm of creation, we start to bump into limits. What if the tool we are given doesn't allow us to say or do what we want? Consider the spreadsheet, a general data management tool. Some people use it simply as a formatted data entry tool, but it is more. Every spreadsheet program gives us a formula language for going beyond what the creators of Excel or Numbers imagined.
But what about the rest of our tools? Must we limit what we say to what our tool affords us -- to what our tool builders afford us?
A computer is not just a tool. It is also a medium of expression, and an increasingly important one.
If you think of programming as C or Java, then the idea of teaching everyone to program may seem silly. Even I am not willing to make that case here. But there are different kinds of programming. Even professional programmers write code at many levels of abstraction, from assembly language to the highest high-level language. Non-programmers such as physicists and economists use scripting languages like Python. Kids of all ages are learning to program Scratch.
Scratch is a good example of what I was thinking when I retweeted. Scratch is programming. But Scratch is really a way to tell stories. Just like writing and speaking.
Alfred Thompson summed up this viewpoint succinctly:
[S]tudents need to be creators and not just consumers.
Kids today understand this without question. They want to make video mash-ups and interactive web pages and cutting-edge presentations. They need to know that they can do more than just use the tools we deign to give them.
One respondent wrote:
As society evolves there is an increasing gap between those that use technology and those that can create technology. Whilst this is a concern, it's not the lowest common denominator for communication: speaking, reading and writing.
The first sentence is certainly true. The question for me is: on which side of this technology divide does computing live? If you think of computation as "just" technology, then the second sentence seems perfectly reasonable. People use Office to do their jobs. It's "just a tool".
It could, however, be a better tool. Many scientists and business people write small scripts or programs to support their work. Many others could, too, if they had the skills. What about teachers? Many routine tasks could be automated in order to give them more time to do what they do best, teach. We can write software packages for them, but then we limit them to being consumers of what we provide. They could create, too.
Is computing "just tech", or more? Most of the world acts like it is the former. The result is, indeed, an ever increasing gap between the haves and the have nots. Actually, the gap is between the can dos and the cannots.
I, and many others, think computation is more than simply a tool. In the wake of Steve Jobs's death last week, many people posted his famous quote that computing is a liberal art. Alan Kay, one of my inspirations, has long preached that computing is a new medium on the order of reading and writing. The list of people in the trenches working to make this happen is too numerous to include.
More practically, software and computer technology are the basis of much innovation these days. If we teach the new medium to only a few, the "5 percent of the population over in the corner" to whom Jobs refers, we exclude the other 95% from participating fully in the economy. That restricts economic growth and hurts everyone. It is also not humane, because it restricts people's personal growth. Everyone has a right to the keys to the kingdom.
I stand in solidarity with the original tweeter and retweeter. Teaching students how to operate software, but not produce software, is like teaching kids to read but not to write. We can do better.
October 10, 2011 2:56 PM
Making Your Own Mistakes
Earlier today, @johndmitchell retweeted a link from Tara "Miss Rogue" Hunt:
RT @missrogue: My presentation from this morning at #ennovation: The 10 Mistakes I've made...so you don't have to http://t.co/QE0DzF9tw

I liked the title and so followed the link to the slide deck. The talk includes a few good quotes and communicates some solid experience on how to fail as a start-up, and also how to succeed. I was glad to have read.
The title notwithstanding, though, be prepared. Other people making mistakes will not -- cannot -- save you from making the same mistakes. You'll have to make them yourself.
There are certain kinds of mistakes that don't need to be made again, but that happens when we eliminate an entire class of problems. As a programmer, I mostly don't have to re-make the mistakes my forebears made when writing code in assembly. They learned from their mistakes and made tools that shield me from the problems I faced. Now, I write code in a higher-level language and let the tools implement the right solution for me.
Of course, that means I face a new class of problems, or an old class of problems in a new way. So I make new kinds of mistakes. In the case of assembly and compilers, I am more comfortable working at that level and am thus glad to have been shielded from those old error traps, by the pioneers who preceded me.
Starting a start up isn't the sort of problem we are able to bypass so easily. Collectively, we aren't good at all at reliably creating successful start-ups. Because the challenges involve other people and economic forces, they will likely remain a challenge well into our future.

Even though Hunt and other people who have tried and failed at start-ups can't save us from making these mistakes, they still do us a service when they reflect on their experiences and share with us. They put up guideposts that say "Danger ahead!" and "Don't go there!"
Why isn't that enough to save us? We may miss the signs in the noise of our world and walk into the thicket on our own. We may see the warning sign, think "My situation is different...", and proceed anyway. We may heed their advice, do everything we can to avoid the pitfall, and fail anyway. Perhaps we misunderstood the signs. Perhaps we aren't smart enough yet to solve the problem. Perhaps no one is, yet. Sometimes, we won't be until we have made the mistake once ourselves -- or thrice.
Despite this, it is valuable to read about our forebears' experiences. Perhaps we will recognize the problem part of the way in and realize that we need to turn around before going any farther. Knowing other people's experiences can leave us better prepared not to go too far down into the abyss. A mistake partially made is often better than a mistake made all the way.
If nothing else, we fail and are better able to recognize our mistake after we have made it. Other people's experience can help us put our own mistake into context. We may be able to understand the problem and solution better by bringing those other experiences to bear on our own experience.
While I know that we have to make mistakes to learn, I don't romanticize failure. We should take reasonable measures to avoid problems and to recognize them as soon as possible. That's the ultimate value in learning what Hunt and other people can teach us.
October 06, 2011 3:21 PM
Programming != Teaching
A few weeks ago I wrote a few entries that made connections to Roger Rosenblatt's Unless It Moves the Human Heart: The Craft and Art of Writing. As I am prone to doing, I found a lot of connections between writing, as described by Rosenblatt, and programming. I also saw connections between teaching of writers and teaching of programmers. The most recent entry in that series highlighted how teachers want their students to learn how to think the same way, not how to write the same way.
Rosenblatt also occasionally explores similarities between writing and teaching. Toward the end of the book, he points out a very important difference between the two:
Wouldn't it be nice if you knew that your teaching had shape and unity, and that when a semester came to an end, you could see that every individual thing you said had coalesced into one overarching statement? But who knows? I liken teaching to writing, but the two enterprises diverge here, because any perception of a grand scheme depends on what the students pick up. You may intend a lovely consistency in what you're tossing them, but they still have to catch it. In fact, I do see unity to my teaching. What they see, I have no clue. It probably doesn't matter if they accept the parts without the whole. A few things are learned, and my wish for more may be plain vanity.
Novelists, poets, and essayists can achieve closure and create a particular whole. Their raw material are words and ideas, which the writer can make to dance. The writer can have an overarching statement in mind, and making it real is just a matter of hard work and time.
Programmers have that sort of control over their raw material, too. As a programmer, I relish taken on the challenge of a hard problem and creating a solution that meets the needs of a person. If I have a goal for a program, I can almost always make it happen. I like that.
Teachers may have a grand scheme in mind, too, but they have no reliable way of making sure that their scheme comes true. Their raw material consists not only of words and ideas. Indeed, their most important raw material, their most unpredictable raw material, are students. Try as they might, teachers don't control what students do, learn, or think.
I am acutely aware of this thought as we wrap up the first half of our programming languages course. I have introduced students to functional programming and recursive programming techniques. I have a pretty good idea what I hope they know and can do now, but that scheme remains in my head.
Rosenblatt is right. It is vanity for us teachers to expect students to learn exactly what we want for them. It's okay if they don't. Our job is to do what we can to help them grow. After that, we have to step aside and let them run.
Students will create their own wholes. They will assemble their wholes from the parts they catch from us, but also from parts they catch everywhere else. This is a good thing, because the world has a lot more to teach than I can teach them on my own. Recognizing this makes it a lot easier for me as a teacher to do the best I can to help them grow and then get out of their way.
October 04, 2011 4:43 PM
Programming in Context: Digital History
Last April I mentioned The Programming Historian, a textbook aimed at a specific set of non-programmers who want or need to learn how to program in order to do their job in the digital age. I was browsing through the textbook today and came across a paragraph that applies to more than just historians or so-called applied programmers:
Many books about programming fall into one of two categories: (1) books about particular programming languages, and (2) books about computer science that demonstrate abstract ideas using a particular programming language. When you're first getting started, it's easy to lose patience with both of these kinds of books. On the one hand, a systematic tour of the features of a given language and the style(s) of programming that it supports can seem rather remote from the tasks that you'd like to accomplish. On the other hand, you may find it hard to see how the abstractions of computer science are related to your specific application.
I don't think this feeling is limited to people with a specific job to do, like historians or economists. Students who come to the university intending to major in Computer Science lose patience with many of our CS1 textbooks and CS1 courses for the very same reasons. Focusing too much on all the features of a language is overkill when you are just trying to make something work. The abstractions we throw at them don't have a home in their understanding of programming or CS yet and so seem, well, too abstract.
Writing for the aspiring applied programmer has an advantage over writing for CS1: your readers have something specific they want to do, and they know just what it is. Turkel and MacEachern can teach a subset of several tools, including Python and Javascript, focused on what historians want to be able to do. Greg Wilson and his colleagues can teach what scientists want and need to know, even if the book is pitched more broadly.
In CS1, your students don't have a specific task in mind and do eventually need to take a systematic tour of a language's features and to learn a programming style or three. They do, eventually, need to learn a set of abstractions and make sense of them in the context of several languages. But when they start, they are much like any other person learning to program: they would like to do something that matters. The problems we ask them to solve matter.
Guzdial, Ericson, and their colleagues have used media computation as context in which to learn how to program, with the idea that many students, CS majors and non-majors alike, can be enticed to manipulate images, sounds, and video, the raw materials out of which students' digital lives are now constructed. It's not quite the same -- students still need to be enticed, rather than starting with their own motivation -- but it's a shorter leap to caring than the run-off-the-mill CS textbook has to make.
Some faculty argue that we need a CS0 course that all students take, in which they can learn basic programming skills in a selected context before moving onto the major's first course. The context can be general enough, say, media manipulation or simple text processing on the web, that the tools students learn will be useful after the course whether they continue on or not. Students who elect to major in CS move on to take a systematic tour of a language's features, to learn about OO or FP style, and to begin learning the abstractions of the discipline.
My university used to follow this approach, back in the early and mid 1990s. Students had to take a one-year HS programming course or a one-semester programming course at the university before taking CS1. We dropped this requirement when faculty began asking, why shouldn't we put the same care into teaching low-level programming skills in CS1 as we do into teaching CS0? The new approach hasn't always been as successful as we hoped, due to the difficulty of finding contexts that motivate students as well as we want, but I think the approach is fundamentally sound. It means that CS1 may not teach all the things that it did when the course had a prerequisite.
That said, students who take one of our non-majors programming courses, C and Visual Basic, and then move decide to major in CS perform better on average in CS1 than students who come in fresh. We have work to do.
Finally, one sentence from The Programming Historian made me smile. It embodies the "programming for all" theme that permeates this blog:
Programming is for digital historians what sketching is for artists or architects: a mode of creative expression and a means of exploration.
I once said that being able to program is like having superhuman strength. But it is both more mundane and more magical than that. For digital historians, being able to program means being able to do the mundane, everyday tasks of manipulating text. It also gives digital historians a way to express themselves creatively and to explore ideas in ways hard to imagine otherwise.
October 03, 2011 8:11 AM
What to Build and How to Build
Update: This entry originally appeared on September 29. I bungled my blog directory and lost two posts, and the simplest way to get the content back on-line is to repost.
I remember back in the late 1990s and early 2000s when patterns were still a hot topic in the software world, and many pattern writers trying to make the conceptual move to pattern languages. It was a fun time to talk about software design. At some point, there was a long and illuminating discussion on the patterns mailing list about whether patterns should describe what to build or how to build. Richard Gabriel and Ron Goldman -- creators of the marvelous essay-as-performance-art Mob Software -- patiently taught the community that the ultimate goal is what. Of course, if we move to a higher level of abstraction, a what-pattern becomes a how-pattern. But the most valuable pattern languages teach us what to build and when, with some freedom in the how.
This is the real challenge that novice programmers face, in courses like CS1 or in self-education: figuring out what to build. It is easy enough for many students to "get" the syntax of the programming language they are learning. Knowing when to use a loop, or a procedure, or a class -- that's the bigger challenge.
Our CS students are usually in the same situation even later in their studies. They are still learning what to build, even as we teach them new libraries, new languages, and new styles.
I see this a lot when students who are learning to program in a functional style. Mentally, many think they are focused on the how (e.g., How do I write this in Scheme?). But when we probe deeper, we usually find that they are really struggling with what to say. We spend some time talking about the problem, and they begin to see more clearly what they are trying to accomplish. Suddenly, writing the code becomes a lot easier, if not downright easy.
This is one of the things I really respect in the How to Design Programs curriculum. Its design recipes give beginning students a detailed, complete, repeatable process for thinking about problems and what they need to solve a new problem. Data, contracts, and examples are essential elements in understanding what to build. Template solutions help bridge the what and the how, but even they are, at the student's current level of abstraction, more about what than how.
The structural recursion patterns I use in my course are an attempt to help students think about what to build. The how usually follows directly from that. As students become fluent in their functional programming language, the how is almost incidental.
October 03, 2011 7:20 AM
Softmax, Recursion, and Higher-Order Procedures
Update: This entry originally appeared on September 28. I bungled my blog directory and lost two posts, and the simplest way to get the content back on-line is to repost.
John Cook recently reported that he has bundled up some of his earlier writings about the soft maximum as a tech report. The soft maximum is "a smooth approximation to the maximum of two real variables":
softmax(x, y) = log(exp(x) + exp(y))
When John posted his first blog entry about the softmax, I grabbed the idea and made it a homework problem for my students, who were writing their first Scheme procedures. I gave them a link to John's page, so they had access to this basic formula as well as a Python implementation of it. That was fine with me, because I was simply trying to help students become more comfortable using Scheme's unusual syntax:
(define softmax
(lambda (x y)
(log (+ (exp x)
(exp y)))))
On the next assignment, I asked students to generalize the definition of softmax to more than two variables. This gave them an opportunity to write a variable arity procedure in Scheme. At that point, they had seen only a couple simple examples of variable arity, such as this implementation of addition using a binary + operator:
(define plus ;; notice: no parentheses around
(lambda args ;; the args parameter in lambda
(if (null? args)
0
(+ (car args) (apply plus (cdr args))) )))
Many students followed this pattern directly for softmax:
(define softmax-var
(lambda args
(if (null? (cdr args))
(car args)
(softmax (car args)
(apply softmax-var (cdr args))))))
Some of their friends tried a different approach. They saw that they could use higher-order procedures to solve the problem -- without explicitly using recursion:
(define softmax-var
(lambda args
(log (apply + (map exp args)))))
When students saw each other's solutions, they wondered -- as students often do -- which one is correct?
John's original blog post on the softmax tells us that the function generalizes as we might expect:
softmax(x1, x2, ..., xn) = log(exp(x1) + exp(x2) + ... + exp(xn))
Not many students had looked back for that formula, I think, but we can see that it matches the higher-order softmax almost perfectly. (map exp args) constructs a list of the exp(xi) values. (apply + ...) adds them up. (log ...) produces the final answer.
What about the recursive solution? If we look at how its recursive calls unfold, we see that this procedure computes:
softmax(x1, softmax(x2, ..., softmax(xn-1, xn)...))
This is an interesting take on the idea of a soft maximum, but it is not what John's generalized definition says, nor is it particularly faithful to the original 2-argument function.
How might we roll our own recursive solution that computes the generalized function faithfully? The key is to realize that the function needs to iterate not over the maximizing behavior but the summing behavior. So we might write:
(define softmax-var
(lambda args
(log (accumulate-exps args))))
(define accumulate-exps
(lambda (args)
(if (null? args)
0
(+ (exp (car args)) (accumulate-exps (cdr args))))))
This solution turns softmax-var into interface procedure and then uses structural recursion over a flat list of arguments. One advantage of using an interface procedure is that the recursive procedure accumulate-exps no longer has to deal with variable arity, as it receives a list of arguments.
It was remarkable to me and some of my students just how close the answers produced by the two student implementations of softmax were, given how different the underlying behaviors are. Often, the answers were identical. When different, they differed only in the 12th or 15th decimal digit. As several blog readers pointed out, softmax is associative, so the two solutions are identical mathematically. The differences in the values of the functions result from the vagaries of floating-point precision.
The programmer in me left the exercise impressed by the smoothness of the soft maximum. The idea is resilient across multiple implementations, which makes it seem all the more useful to me.
More important, though, this programming exercise led to several interesting discussions with students about programming techniques, higher-order procedures, and the importance of implementing solutions that are faithful to the problem domain. The teacher in me left the exercise pleased.
Posted by Eugene Wallingford | Permalink | Categories: Computing, Software Development, Teaching and Learning
October 02, 2011 5:16 PM
Computing Everywhere: Economist Turns Programmer
This About Me page, on Ana Nelson's web site, is a great example of how computing can sneak up on people:
Having fallen in love with programming while studying for my Ph.D. in economics, I now develop open source software to explore and explain data. I am the creator of Dexy, a new tool for reproducible research and document automation.
A lot of disciplines explore and explain data, from particular domains and within particular models. I'm not surprised when I encounter someone in one of those disciplines who finds she likes exploring and explaining data more than the specific domain or model. Programming is a tool that lets rise above disciplinary silos and consider data, patterns, and ideas across the intellectual landscape.