December 24, 2013 11:35 AM
Inverting the Relationship Between Programs and Literals
This chapter on quasi-literals in the E language tells the story of Scott Kim teaching the author that Apple's HyperCard was "powerful in a way most of had not seen before". This unexpected power led many people to misunderstand its true importance.
Most programs are written as text, sequences of characters. In this model, a literal is a special form of embedded text. When the cursor is inside the quotes of a literal string, we are "effectively no longer in a program editor, but in a nested text editor". Kim calls this a 'pun': Instead of writing text to be evaluated by another program, we are creating output directly.
What if we turn things inside out and embed our program in literal text?
Hypercard is normally conceived of as primarily a visual application builder with an embedded silly programming language (Hypertalk). Think instead of a whole Hypercard stack as a mostly literal program. In addition to numbers and strings, the literals you can directly edit include bitmaps, forms, buttons, and menus. You can literally assemble most things, but where you need dynamic behavior, there's a hole in the literal filled in by a Hypertalk script. The program editor for this script is experienced as being nested inside the direct manipulation user interface editor.
There is a hole in the literal text, where a program goes, instead of a hole in the program, where literal text goes.
HyperTalk must surely have seemed strange to most programmers in 1987. Lisp programmers had long used macros and so knew the power of nesting code to be eval'ed inside of literal text. Of course, the resulting text was then passed on the eval to be treated again as program!
The inside-out idea of HyperCard is alive today in the form of languages such as PHP, which embed code in HTML text:
<body>
<?php
echo $_SERVER['HTTP_USER_AGENT'];
?>
</body>
This is a different way to think about programming, one perhaps suitable for bringing experts in some domains toward the idea of writing code gradually from documents in their area of expertise.
I sometimes have the students in my compiler course implement a processor for a simple Mustache-like template language as an early warm-up homework assignment. I do not usually require them to go as far as Turing-complete embedded code, but they create a framework that makes it possible. I think I'll look for ways to bring more of this idea into the next offering of our more general course on programming languages.
(HyperCard really was more than many people realized at the time. The people who got it became Big Fans, and the program still has an ardent following. Check out this brief eulogy, which rhapsodizes on "the mystically-enchanting mantra" at the end of the application's About box: "A day of acquaintance, / And then the longer span of custom. / But first -- / The hour of astonishment.")
December 20, 2013 3:01 PM
Sometimes, Good Design is Simple
In an article on the Moonpig billing system, Mark Dominus writes:
Sometimes I see other people [screw] up a project over and over, and I say "I could do that better", and then I get a chance to try, and I discover it was a lot harder than I thought, I realize that those people who tried before are not as stupid as as I believed.
That did not happen this time.
Sometimes, good design is pretty simple. Separate interface from implementation. Create simple abstraction layers to separate different levels of functionality. Encapsulate data and behavior in objects that circumscribe potential change.
I liked a few of the specific tactics described, too:
Don't use raw primitives from the language, even standard classes. "Instead of using raw DateTime [a standard Perl class], we wrapped it in a derived class called Moonpig::DateTime."
Define convenience functions that hide underlying data implementations. Moonpig does this in several places, most notably money and time.
Use mutable data sparingly, and never for values. One way Moonpig does this is to implement "values with history", an idea I first learned from Ralph Johnson in Smalltalk. Each new value for an entity is pushed onto an array. When a piece of code asks for the current value, it receives the top of the array.
Object-oriented programming is centered around objects. That means encapsulated behavior. Other concepts, such as classes and inheritance, are add-ons. Dominus is especially hard on inheritance, based on past experience. I agree that it must be used carefully and sparingly. I like how Moonpig uses roles to eliminate the need for classes entirely in the application.
This was a fun read.
December 18, 2013 3:31 PM
Favorite Passages from Today's Reading
From The End of the Facebook Era:
This is why social networks [like Google+] are struggling even more than Facebook to get a foothold in the future of social networking. They are betting on last year's fashion -- they're fighting Facebook for the last available room on the Titanic when they should be looking at all of the other ships leaving the marina.
A lot of people and organizations in this world are fighting over the last available room on their sector's version of the Titanic. Universities may well be among them. Who is leaving the marina?
From We Need to Talk About TED:
Astrophysics run on the model of American Idol is a recipe for civilizational disaster.
...
TED's version [of deep technocultural shift] has too much faith in technology, and not nearly enough commitment to technology. It is placebo technoradicalism, toying with risk so as to re-affirm the comfortable.
I like TED talks as much as the next person, but I often wonder how much change they cause in the world, as opposed to serving merely as chic entertainment for the comfortable First World set.
December 17, 2013 3:32 PM
Always Have At Least Two Alternatives
Paraphrasing Kent Beck:
Whenever I write a new piece of code, I like to have at least two alternatives in mind. That way, I know I am not doing the worst thing possible.
I heard Kent say something like this at OOPSLA in the late 1990s. This is advice I give often to students and colleagues, but I've never had a URL that I could point them to.
It's tempting for programmers to start implementing the first good idea that comes to mind. It's especially tempting for novices, who sometimes seem surprised that they have even one good idea. Where would a second one come from?
More experienced students and programmers sometimes trust their skill and experience a little too easily. That first idea seems so good, and I'm a good programmer... Famous last words. Reality eventually catches up with us and helps us become more humble.
Some students are afraid: afraid they won't get done if they waste time considering alternatives, or afraid that they will choose wrong anyway. Such students need more confidence, the kind born out of small successes.
I think the most likely explanation for why beginners don't already seek alternatives is quite simple. They have not developed the design habit. Kent's advice can be a good start.
One pithy statement is often enough of a reminder for more experienced programmers. By itself, though, it probably isn't enough for beginners. But it can be an important first step for students -- and others -- who are in the habit of doing the first thing that pops into their heads.
Do note that this advice is consistent with XP's counsel to do the simplest thing that could possibly work. "Simplest" is a superlative. Grammatically, that suggests having at least three options from which to choose!
Posted by Eugene Wallingford | Permalink | Categories: General, Software Development, Teaching and Learning
December 16, 2013 2:20 PM
More Fun with Integer "Assembly Language": Brute-Forcing a Function Minimum
Or: Irrational Exuberance When Programming
My wife and daughter laughed at me yesterday.
A few years ago, I blogged about implementing Farey sequences in Klein, a language for which my students at the time were writing a compiler. Klein was a minimal functional language with few control structures, few data types, and few built-in operations. Computing rational approximations using Farey's algorithm was a challenge in Klein that I likened to "integer assembly programming".
I clearly had a lot of fun with that challenge, especially when I had the chance to watch my program run using my students' compilers.
This semester, I am again teaching the compiler course, and my students are writing a compiler for a new version of Klein.
Last week, while helping my daughter with a little calculus, I ran across a fun new problem to solve in Klein:
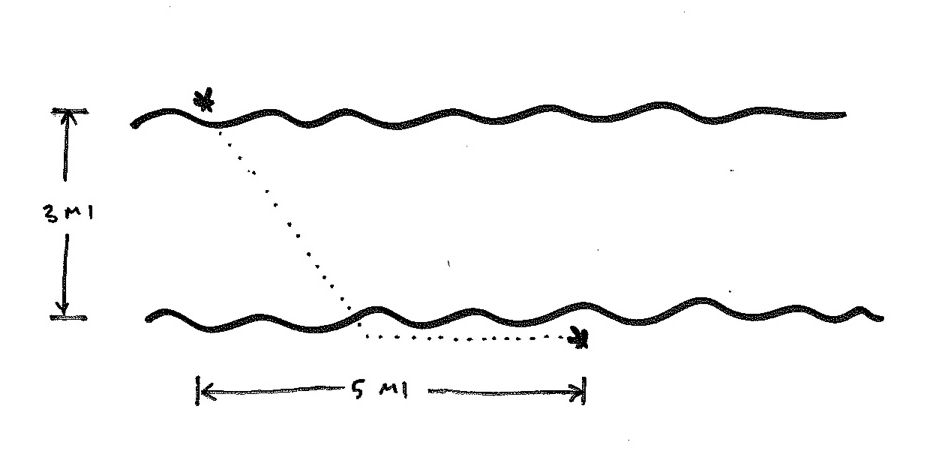
There are two stations on opposite sides of a river. The river is 3 miles wide, and the stations are 5 miles apart along the river. We need to lay pipe between the stations. Pipe laid on land costs $2.00/foot, and pipe laid across the river costs $4.00/foot. What is the minimum cost of the project?
This is the sort of optimization problem one often encounters in calculus textbooks. The student gets to construct a couple of functions, differentiate one, and find a maximum or minimum by setting f' to 0 and solving.
Solving this problem in Klein creates some of challenges. Among them are that ideally it involves real numbers, which Klein doesn't support, and that it requires a square root function, which Klein doesn't have. But these obstacles are surmountable. We already have tools for computing roots using Newton's method in our collection of test programs. Over a 3mi-by-5mi grid, an epsilon of a few feet approximates square roots reasonably well.
My daughter's task was to use the derivative of the cost function but, after talking about the problem with her, I was interested more in "visualizing" the curve to see how the cost drops as one moves in from either end and eventually bottoms out for a particular length of pipe on land.
So I wrote a Klein program that "brute-forces" the minimum. It loops over all possible values in feet for land pipe and compares the cost at each value to the previous value. It's easy to fake such a loop with a recursive function call.
The programmer's challenge in writing this program is that Klein has no local variables other function parameters. So I had to use helper functions to simulate caching temporary variables. This allowed me to give a name to a value, which makes the code more readable, but most importantly it allowed me to avoid having to recompute expensive values in what was already a computationally-expensive program.
This approach creates another, even bigger challenge for my students, the compiler writers. My Klein program is naturally tail recursive, but tail call elimination was left as an optional optimization in our class project. With activation records for all the tail calls stored on the stack, a compiler has to use a lot of space for its run-time memory -- far more than is available on our default target machine.
How many frames do we need? Well, we need to compute the cost at every foot along a (5 miles x 5280 feet/mile) rectangle, for a total of 26,400 data points. There will, of course, be other activation records while computing the last value in the loop.
Will I be able to see the answer generated by my program using my students' compilers? Only if one or more of the teams optimized tail calls away. We'll see soon enough.
So, I spent an hour or so writing Klein code and tinkering with it yesterday afternoon. I was so excited by the time I finished that I ran upstairs to tell my wife and daughter all about it: my excitement at having written the code, and the challenge it sets for my students' compilers, and how we could compute reasonable approximations of square roots of large integers even without real numbers, and how I implemented Newton's method in lieu of a sqrt, and...
That's when my wife and daughter laughed at me.
That's okay. I am programmer. I am still excited, and I'd do it again.
December 11, 2013 12:01 PM
"Costs $20" is Functionally Indistinguishable from Gone
In his write-up on the origin of zero-based indexing in computing, Mike Hoye comments on the difficulties he had tracking down original sources:
Part of the problem is access to the historical record, of course. I was in favor of Open Access publication before, but writing this up has cemented it: if you're on the outside edge of academia, $20/paper for any research that doesn't have a business case and a deep-pocketed backer is completely untenable, and speculative or historic research that might require reading dozens of papers to shed some light on longstanding questions is basically impossible. There might have been a time when this was OK and everyone who had access to or cared about computers was already an IEEE/ACM member, but right now the IEEE -- both as a knowledge repository and a social network -- is a single point of a lot of silent failure. "$20 for a forty-year-old research paper" is functionally indistinguishable from "gone", and I'm reduced to emailing retirees to ask them what they remember from a lifetime ago because I can't afford to read the source material.
I'm an academic. When I am on campus, I have access to the ACM Digital Library. When I go home, I do not. I could pay for a personal subscription, but that seems an unnecessary expense when I am on campus so much.
I never have access to IEEE Xplore, Hoy's "single point of silent failure". Our university library chose to drop its institutional subscription a few years ago, and for good reason: it is ridiculously expensive, especially relative to the value we receive from it university-wide. (We don't have an engineering college.) We inquired about sharing a subscription with our sister schools, as we are legally under a single umbrella, but at least at that time, IEEE didn't allow such sharing.
What about non-academics, such as Hoye? We are blessed in computing with innumerable practitioners who study our history, write about, and create new ideas. Some are in industry and may have access to these resources, or an expense account. Many others, though, work on their own as independent contractors and researchers. They need access to materials, and $20 a pop is an acceptable expense.
Their loss if our loss. If Hoye had not written his article on the history of zero-based indexing, most of us wouldn't know the full story.
As time goes by, I hope that open access to research publications continues to grow. We really shouldn't have to badger retired computer scientists with email asking what they remember now about a topic they wrote an authoritative paper on forty years ago.
December 10, 2013 3:33 PM
Your Programming Language is Your Raw Material, Too
Recently someone I know retweeted this familiar sentiment:
If carpenters were hired like programmers:
"Must have at least 5 years experience with the Dewalt 18V 165mm Circular Saw"
This meme travels around the world in various forms all the time, and every so often it shows up in one of my inboxes. And every time I think, "There is more to the story."
In one sense, the meme reflects a real problem in the software world. Job ads often use lists of programming languages and technologies as requirements, when what the company presumably really wants is a competent developer. I may not know the particular technologies on your list, or be expert in them, but if I am an experienced developer I will be able to learn them and become an expert.
Understanding and skill run deeper than a surface list of tools.
But. A programming language is not just a tool. It is a building material, too.
Suppose that a carpenter uses a Dewalt 18V 165mm circular saw to add a room to your house. When he finishes the project and leaves your employ, you won't have any trace of the Dewalt in his work product. You will have a new room.
He might have used another brand of circular saw. He may not have used a power tool at all, preferring the fine craftsmanship of a handsaw. Maybe he used no saw of any kind. (What a magician!) You will still have the same new room regardless, and your life will proceed in the very same way.
Now suppose that a programmer uses the Java programming language to add a software module to your accounting system. When she finishes the project and leaves your employ, you will have the results of running her code, for sure. But you will have a trace of Java in her work product. You will have a new Java program.
If you intend to use the program again, to generate a new report from new input data, you will need an instance of the JVM to run it. If want to modify the program to work differently, then you will also need a Java compiler to create the byte codes that run in the JVM. If you want to extend the program to do more, then you again will need a Java compiler and interpreter.
Programs are themselves tools, and we use programming languages to build them. So, while the language itself is surely a tool at one level, at another level it is the raw material out of which we create other things.
To use a particular language is to introduce a slew of other dependencies to the overall process: compilers, interpreters, libraries, and sometimes even machine architectures. In the general case, to use a particular language is to commit at least some part of the company's future attention to both the language and its attendant tooling.
So, while I am sympathetic to sentiment behind our recurring meme, I think it's important to remember that a programming language is more than just a particular brand of power tool. It is the stuff programs are made of.
December 08, 2013 11:48 AM
Change Happens When People Talk to People
I finally got around to reading Atul Gawande's Slow Ideas this morning. It's a New Yorker piece from last summer about how some good ideas seem to resist widespread adoption, despite ample evidence in their favor, and ways that one might help accelerate their spread.
As I read, I couldn't help but think of parallels to teaching students to write programs and helping professionals develop software more reliably. We know that development practices such as version control, short iterations, and pervasive testing lead to better software and more reliable process. Yet they are hard habits for many programmers to develop, especially when they have conflicting habits in place.
Other development practices seem counterintuitive. "Pair programming can't work, right?" In these cases, we have to help people overcome both habits of practice and habits of thought. That's a tall order.
Gawande's article is about medical practice, from surgeons to home practitioners, but his conclusions apply to software development as well. For instance: People have an easier time changing habits when the benefit is personal, immediate, and visceral. When the benefit is not so obvious, a whole new way of thinking is needed. That requires time and education.
The key message to teach surgeons, it turned out, was not how to stop germs but how to think like a laboratory scientist.
This is certainly true for software developers. (If you replace "germs" with "bugs", it's an even better fit!) Much of the time, developers have to think about evidence the ways scientists do.
This lesson is true not just for surgeons and software developers. It is true for most people, in most ways of life. Sometimes, we all have to be able to think and act like a scientist. I can think of no better argument for treating science as important for all students, just as we do reading and writing.
Other lessons from Gawande's article are more down-to-earth:
Many of the changes took practice for her, she said. She had to learn, for instance, how to have all the critical supplies -- blood-pressure cuff, thermometer, soap, clean gloves, baby respiratory mask, medications -- lined up and ready for when she needed them; how to fit the use of them into her routine; how to convince mothers and their relatives that the best thing for a child was to be bundled against the mother's skin. ...
So many good ideas in one paragraph! Many software development teams could improve by putting them in action:
- Construct a work environment with essential tools ready at hand.
- Adjust routine to include new tools.
- Help collaborators see and understand the benefit of new habits.
- Practice, practice, practice.
Finally, the human touch is essential. People who understand must help others to see and understand. But when we order, judge, or hector people, they tend to close down the paths of communication, precisely when we need them to be most open. Gawande's colleagues have been most successful when they built personal relationships:
"It wasn't like talking to someone who was trying to find mistakes," she said. "It was like talking to a friend."
Good teachers know this. Some have to learn it the hard way, in the trenches with their students. But then, that is how Gawande's colleagues learned it, too.
"Slow Hands" is good news for teachers all around. It teaches ways to do our job better. But also, in many ways, it tells us that teaching will continue to matter in an age dominated by technological success:
People talking to people is still how the world's standards change.
Posted by Eugene Wallingford | Permalink | Categories: Managing and Leading, Software Development, Teaching and Learning
December 04, 2013 3:14 PM
Agile Moments, "Why We Test" Edition
Case 1: Big Programs.
This blog entry tells the sad story of a computational biologist who had to retract six published articles. Why? Their conclusions depended on the output of a computer program, and that program contained a critical error. The writer of the entry, who is not the researcher in question, concludes:
What this should flag is the necessity to aggressively test all the software that you write.
Actually, you should have tests for any program you use to draw important conclusions, whether you wrote it or not. The same blog entry mentions that a grad student in the author's previous lab had found several bugs a molecular dynamics program used by many computational biologists. How many published results were affected before they were found?
Case 2: Small Scripts.
Titus Brown reports finding bugs every time he reused one of his Python scripts. Yet:
Did I start doing any kind of automated testing of my scripts? Hell no! Anyone who wants to write automated tests for all their little scriptlets is, frankly, insane. But this was one of the two catalysts that made me personally own up to the idea that most of my code was probably somewhat wrong.
Most of my code has bugs but, hey, why write tests?
Didn't a famous scientist define insanity as doing the same thing over and over but expecting different results?
I consider myself insane, too, but mostly because I don't write tests often enough for my small scripts. We say to ourselves that we'll never reuse them, so we don't need tests. But we don't throw them away, and then we do reuse them, perhaps with a tweak here or there.
We all face time constraints. When we run a script the first time, we may well pay enough attention to the output that we are confident it is correct. But perhaps we can all agree that the second time we use a script, we should write tests for it if we don't already have them.
There are only three numbers in computing, 0, 1, and many. The second time we use a program is a sign from the universe that we need the added confidence provided by tests.
To be fair, Brown goes on to offer some good advice, such as writing tests for code after you find a bug in it. His article is an interesting read, as is almost everything he writes about computation and science.
Case 3: The Disappointing Trade-Off.
Then there's this classic from Jamie Zawinski, as quoted in Coders at Work:
I hope I don't sound like I'm saying, "Testing is for chumps." It's not. It's a matter of priorities. Are you trying to write good software or are you trying to be done by next week? You can't do both.
Sigh. If you you don't have good software by next week, maybe you aren't done yet.
I understand that the real world imposes constraints on us, and that sometimes worse is better. Good enough is good enough, and we rarely need a perfect program. I also understand that Zawinski was trying to be fair to the idea of testing, and that he was surely producing good enough code before releasing.
Even still, the pervasive attitude that we can either write good programs or get done on time, but not both, makes me sad. I hope that we can do better.
And I'm betting that the computational biologist referred to in Case 1 wishes he had had some tests to catch the simple error that undermined five years worth of research.
December 03, 2013 3:17 PM
The Workaday Byproducts of Striving for Higher Goals
Why set audacious goals? In his piece about the Snowfall experiment, David Sleight says yes, and not simply for the immediate end:
The benefits go beyond the plainly obvious. You need good R&D for the same reason you need a good space program. It doesn't just get you to the Moon. It gives you things like memory foam, scratch-resistant lenses, and Dustbusters. It gets you the workaday byproducts of striving for higher goals.
I showed that last sentence a little Twitter love, because it's something people often forget to consider, both when they are working in the trenches and when they are selecting projects to work on. An ambitious project may have a higher risk of failure than something more mundane, but it also has a higher chance of producing unexpected value in the form of new tools and improved process.
This is also something that university curricula don't do well. We tend to design learning experiences that fit neatly into a fifteen-week semester, with predictable gains for our students. That sort of progress is important, of course, but it misses out on opportunities for students to produce their own workaday byproducts. And that's an important experience for students to have.
It also gives a bad example of what learning should feel like, and what it should do for us. Students generally learn what we teach them, or what we make easiest for them to learn. If we always set before them tasks of known, easily-understood dimensions, then they will have to learn after leaving us that the world doesn't usually work like that.
This is one of the reasons I am such a fan of project-based computer science education, as in the traditional compiler course. A compiler is an audacious enough goal for most students that they get to discover their own personal memory foam.
Posted by Eugene Wallingford | Permalink | Categories: General, Software Development, Teaching and Learning