Last time, I opened with a story, the beginning of Turing's seminal paper "Computing Machinery and Intelligence".
I propose to consider the question, "Can machines think?" ...
If you ever are looking for a way to kill a few minutes in an interesting way some Friday night, try playing this parlor game. Choose four participants: an interrogator, a man, woman, and a "runner" who acts as a teletype. (Better yet, try it using Unix 'talk'!) Your runner's responses should be 'practiced' enough so as not to give anything away. Play for five, ten, or fifteen minutes.
Of course, these days, many of you already have an experience akin to Turing's imitation game: meeting folks in chat rooms and carrying on extended discussions. And I am sure that many times you wonder, "Can this guy be for real??" Turing would be proud. :-)
Before proceeding, spend some time answering the following questions:
In his paper, Turing anticipates some objections to his game and to the proposition that machines can think if they can play the game as well as a man:
(I have omitted (9) The Argument from Extrasensory Perception. Is that fair? Is it reasonable?)
Most of these arguments are "Yes, but..." objections--they object to the very question "Can machines think?" Perhaps the strongest of these are the consolidated Arguments from Various Disabilities. People who adopt this stance identify a particular skill or behavior that humans exhibit and then claim that computers cannot exhibit the same. But one would have to justify why that is so, and most folks in trying to do so fall back on one of the other, less convincing objections. Turing proposes that people are really using an invalid form of induction when they draw this conclusion in the first place.
The The Argument from Consciousness comes closest to questioning the validity of the game itself. Consider what Turing himself says in reply to it:
This argument is very well expressed in Professor Jefferson's Lister Oration for 1949, from which I quote. "Not until a machine can write a sonnet or compose a concerto because of thoughts and emotions felt, and not by the chance fall of symbols, could we agree that machine equals brain--that is, not only write it but know that it had written it. No mechanism could feel (and not merely artificially signal, an easy contrivance) pleasure at its successes, grief when its valves fuse, be warmed by flattery, be made miserable by its mistakes, be charmed by sex, be angry or depressed when it cannot get what it wants."This argument appears to be a denial of the validity of our test. According to the most extreme form of this view the only way by which one could be sure that machine thinks is to be the machine and to feel oneself thinking. One could then describe these feelings to the world, but of course no one would be justified in taking any notice. Likewise according to this view the only way to know that a man thinks is to be that particular man. It is in fact the solipsist point of view. It may be the most logical view to hold but it makes communication of ideas difficult. A is liable to believe "A thinks but B does not" whilst B believes "B thinks but A does not." instead of arguing continually over this point it is usual to have the polite convention that everyone thinks.
I am sure that Professor Jefferson does not wish to adopt the extreme and solipsist point of view. Probably he would be quite willing to accept the imitation game as a test. The game (with the player B omitted) is frequently used in practice under the name of viva voce to discover whether some one really understands something or has "learnt it parrot fashion." Let us listen in to a part of such a viva voce:
Interrogator: In the first line of your sonnet which reads "Shall I compare thee to a summer's day," would not "a spring day" do as well or better?
Witness: It wouldn't scan.
Interrogator: How about "a winter's day," That would scan all right.
Witness: Yes, but nobody wants to be compared to a winter's day.
Interrogator: Would you say Mr. Pickwick reminded you of Christmas?
Witness: In a way.
Interrogator: Yet Christmas is a winter's day, and I do not think Mr. Pickwick would mind the comparison.
Witness: I don't think you're serious. By a winter's day one means a typical winter's day, rather than a special one like Christmas.
And so on, What would Professor Jefferson say if the sonnet-writing machine was able to answer like this in the viva voce?
The sort of interrogation that Turing calls viva voce should sound familiar. Teachers do it all of the time, to assess whether a student understands something. The whole Oxonian tradition of tutorials is based on this sort of interaction. Considered this way, my reference to chat rooms above doesn't seem so silly after all!
If a program could carry out such a dialogue with an informed human in one or more areas, could we in any fairness say the program isn't intelligent?
I think that it is untenable to say that a program playing Turing's parlor game well--behaving in the spirit of the game--is not intelligent. Choosing to do so is, in my opinion, a choice to deny a possibility solely because we can't or don't want to imagine a world different than the one we are used to. That isn't a scientific attitude at all.
But what of the game itself?
Before proceeding, spend some time answering the following questions:
What might be wrong with the Turing Test as an evaluator of intelligence?
Turing's game makes some assumptions about what counts as intelligent. Linguistic skills are essential, but social and physical skills are not. Does this leave out anything essential or useful? It focuses largely on cognitive skills and seems to leave out other behaviors we might consider intelligent, such as the ability to lead or collaborate.
Some folks claim that Turing's game emphasizes a behavior that we do not consider essential to intelligence, such as ones that do no more than fool the interrogator. As an example, consider the solution of difficult mathematics problems... We think of computers as infallible on such matters as high-speed arithmetic. Would we really want to build in error-prone behaviors? They wouldn't help us to determine whether the program is intelligent, only that it is like a human!
I think that Turing's game, as adapted to computers and humans, does a pretty good job of evaluating the behaviors that Turing seems to assume are intelligent: cognitive tasks and linguistic expressiveness. We'll consider this question again below...
This, too, requires some elaboration. Let's save it for later, too.
One of the first problems many people have with Turing's game is that it defines out of intelligence behaviors that aren't strictly cognitive. Is there a distinction between thinking and behavior?
What does Turing's game isolate, if not intelligence?
We still have a hard time defining intelligence--and thus artificial intelligence--today. People who present narrow definitions are usually taken to task, and most of the broader definitions (Gardner's and Root-Bernstein's, for instance) seem rather nebulous and untestable at this point.
Another complication is that the boundaries between what machines can and cannot do continuously move, so the research frontier does, too. (Remember Minsky's definition of AI...)
Since many other disciplines also concern themselves with intelligence, thought, and rationality, AI draws from a wide assortment of ideas: linguistics, psychology, philosophy, mathematics, physiology, neurology, prosthetics, and engineering--and we haven't even mentioned computer science yet!
The Turing Test evokes the dominant naive view of intelligence in the world, and thus of AI: the ability to act like a human. (Here, "naive" means uninformed or uninitiated in the ways of cognitive science.) It sidesteps the attempt to define intelligence and instead attempts to operationalize it.
The Turing Test seems to identify human-like behavior and human-like experience. To play the game well is to use language as we do, to exhibit strengths and weaknesses similar to humans, and to reproduce the peculiarities of human hardware.
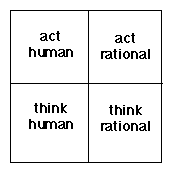
For this reason, the authors of another popular AI textbook (Russell and Norvig) characterize the Turing Test as the "Acting Humanly" view of AI. They consider four possible views of AI, in two dimensions:
I called it "naive" view, in the sense that it corresponds to the view of intelligence held by most lay people. Turing's genius in this paper is that he gets to the heart of the naive view in such a way that a most fascinating academic and practical discipline emerges.
Turing created an argument that most people could understand. In modern times, Hayes and Ford have distinguished between two styles of Turing Test: the gender test, following Turing's original formulation, and the species test, which captures Turing's intent but sidesteps spurious gender-related questions. We have had some fun in previous semesters with this sort of problem. (Besides, what does "successfully take the place of the man" mean anyway?? :-)
These days, the Turing Test is generally framed as a species test: A judge interacts with a human and a machine. The computer is successful if the judge cannot determine which is which after a protracted interaction. Sometimes this is a "mano a mano" game, and other times it occurs in more elaborate scenarios.
If you care to see some of the other objections that Turing considers and rebuts, read the paper. The breadth of Turing's coverage is quite a work of mind! And it is readable, too.
However, one can raise some more technical objections against the Turing Test. Hayes and Ford suggest a couple:
Assume that the human subject in the species test is the "control" agent, and the machine is the "experimental" agent. The designer of the experimental entity is "successful" if the judge supports the hypthesis "machine behavior = human behavior" -- the null hypothesis. You might think of this sort of Turing Test as a proof by confirmation of equivalence (of machine and human) by looking at a finite number of separate behaviors of each subject.
One problem with the Turing Test, as they see it, is that it tests the judge as much if not more than it tests the machine. Perhaps the judge simply didn't try hard enough or know enough to discriminate between the two.
Folks who like the Turing Test as an operational definition of AI often address this objection by adding "reliably" to their statements of the definition. I agree with these folks. I won't comment on the validity of the experimental design (mostly because I don't care! :-), but think of it this way:
Suppose that you carried on a long-term correspondence with a pen pal, say for thirty years or more. And then someone told you that your pen pal was actually a computer program running on a TRS-80. This is Turing's idea taken to the extreme, minus the artificial deadlines. What would you think? And how would you feel?
Of course, Hayes and Ford are not without ammunition in response. They ask us to consider the gender test, and a finding by Lakoff that women use more different color words then men (e.g., women are more likely to use words such as "scarlet" and "crimson", and men are more likely just to say "red"). Is the judge aware of this? Does the judge exploit this difference in discriminating a man/machine from a woman? Was the designer of the machine aware of this and did she exploit it? Is it desirable to study this minutiae for the sole purpose of winning the gender contest? (Any "Trivial Pursuit" players in the room?)
As an example both of my analogy and the Ford/Hayes objection, consider Eliza, a program written by Joseph Weizenbaum in the late 60's that takes the role of a psychoanalyst in a psychiatric interview. Here is a sample dialogue that captures the flavor of a real dialogue with ELIZA:
ELIZA is a relatively simple pattern-matching program; it takes keywords from a subject's response and inserts these into one of a set of "skeletal" responses to the subject. (You folks in the lab will probably see an Eliza knock-off in a few weeks.) The fact that the computer seems to understand the subject's statements is an illusion. Weizenbaum found, however, that users were taking their sessions with ELIZA quite seriously. An amusing anecdote is that one day Weizenbaum walked in on his secretary in the middle of a dialogue with ELIZA, and she asked him to leave so that the dialog could continue in privacy. This scared Weizenbaum a bit and sparked a change in his views on AI.
The point here is that apparently users of ELIZA were easily fooled by the illusion that ELIZA comprehended the discussion. These users were judges, though not in the context of a Turing Test per se, who simply didn't work very hard. As a sidenote, Weizenbaum is now a critic of AI who has not typically argued against the possibility of AI, but--in part because of his experience with ELIZA--he argues against the desire for AI on ethical grounds. For more, seee his book: Computer Power and Human Thought.
So, even though I think that this objection is insufficient to strike the Turing Test, I find the issue is complex enough to consider further discussion. That's what we get for studying hard problems, especially in young sciences: There aren't many clear-cut answers.
This idea that judges may be easily fooled leads to this, a second objection from Ford and Hayes. Consider:
The Loebner competition is a yearly event that pits machines against humans in Turing Tests. Eventually, a $100,000 (?) prize may be claimed by a machine that passes a general Turing Test. Currently, contestants are allowed to compete in circumstances where the topic of discourse is limited--say, to the latest White House scandal. The winner of the Loebner prize in 1995 deliberately misspelled words, backed up over text to correct, and typed at human speed. This is clever, but not the kind of thing that we want to be studying as AI.
Another amusing anecdote: Hayes and Ford note that, at an earlier Turing Test staged for the Loebner Prize, several judges rated a human as a machine, because the human subject responded with complete, well-written, and informative paragraphs! Would William F. Buckley be judged a machine because he knows the English language too well (e.g., big words like "opalescent" and not to end a sentence with a preposition)?? What does this say about people??
Once again, I disagree that this objection knocks out the Turing Test. As scientists, we have a charge to "do the right thing", and writing such programs ain't it. This objection says nothing about AI, nor about the use of the Turing Test as an operational test of AI. It is an objection to misuse of the technology.
Here is an objection that also draws its juice from something pragmatic, not the test itself:
Success at the Turing Test is a moving target. As AI makes progress, judges come to note this progress and the computational mechanisms responsible for it--and the difficulty in passing the Turing Test increases.
Consider Deep Blue, the IBM-sponsored computer that defeated (ahem) world chess champion Garry Kasparov in the spring of 1997. Many critics of AI and many chess masters are aware that Deep Blue uses search-intensive mechanisms for the bulk of its play and uses abstract knowledge only sparingly. So they say "That's not AI" or "That's not real chess".
Is that fair? If yes, then AI will never be achieved. But we will end up with an even longer list of non-AI results from AI research. :-)
Despite all the objections one can raise to the Turing Test, there is something seductive about its allure (more evidence of Turing's genius). Even though I don't believe that the TT is ultimately the best test for research in AI, something tells me that if we are ever able to create a truly generally intelligent agent it will be able to pass the Turing Test in the way Turing imagined it.
I have mostly defended the Turing Test so far in this discussion, but I don't subscribe to it as a way to define AI. Ultimately, I am unsatisfied for three reasons:
All that said, I love to re-read Turing's paper every fall and think about the issues he raises.
As I mentioned last time, this is the definition of AI I prefer:
Artificial intelligence is the computational study of how a system can perceive, reason, and act in complex environments.
To make this definition useful, we need to operationalize terms like "perceive", "reason", "act", "complex", and "environment". These are doable; for example, we will begin to characterize complexity next week when we investigate the topic of state-space search. This definition gives me a more explicit statement of what we in AI are doing. Perhaps the folks who like the Turing Test would find its explicitness limiting.