Session 14
An Application of Structural Recursion: A Small Interpreter
Opening Exercise: Variable Binding
(f x) (lambda (x)
y)
(lambda (x) ((lambda (x) x)
(f x)) (lambda (x) y))
(a
(lambda (z)
(lambda (x) (lambda (y)
(lambda (x) (lambda (x)
x)) x))))
Try writing a function named (unused-vars exp) to
solve this problem for you, or a function named
(unused-var? v exp) to determine if a particular
variable is declared and not used. Writing these functions may
help you understand the idea of used and unused variables. They
will also be good practice for Quiz 2.
These are also fine test cases for Problem 4 on Homework 6.

Yesterday, Today, Tomorrow
Where We've Been
For the last few weeks, we have been discussing different
techniques for writing recursive programs, all based on the
fundamental technique of structural recursion. Last time,
we applied these techniques in writing a recursive program to
answer this question about programs in
our little language
from Session 12: Does a particular variable occur bound in a given
piece of code? Our program,
(occurs-bound? var exp),
was mutually recursive with the function occurs-free?
because the definitions of bound and free occurrences are
mutually inductive.
In order to think and write more clearly about the little language, we used a new design pattern, Syntax Procedures, which allowed us to focus on the meaning of our data rather than their implementation in Racket.
Where We're Going
The next two units of the course explore important concepts in the design of programming languages, syntactic abstraction and data abstraction, by adding features to our little language and writing Racket code to process them. But our little language is so simple that it can be easy to lose track of where we are heading: the ability to write an interpreter for a programming language that actually does something.
Where We Are
Today, we use some of the ideas we have learned about Racket and recursive programming to implement an interpreter for a small language that actually does something, however simple. This trip has three goals: First, along the way, we'll see how we can begin to use the techniques we've been learning to write larger programs. Second, we'll see ways in which the things we will learn over the next few weeks fit into a language interpreter. Finally, we'll even take a few short breaks to have you write functions of your own, as practice.
The Cipher Language
Cipher is a simple language for encoding text. It has a one unary operator and two infix binary operators:
(rot13 "Hello, Eugene")
("Hello, " + "Eugene")
("Eugene" take 3)
("Eugene" drop 4)
I have written a function named value that evaluates
Cipher expressions. The parentheses in Cipher make it easy to
pass a Cipher expression to the function as a Racket list:
$ racket Welcome to Racket v8.5 [cs]. > (require "cipher-v1.rkt") > (value '(rot13 "Hello, Eugene")) "Uryyb, Rhtrar"
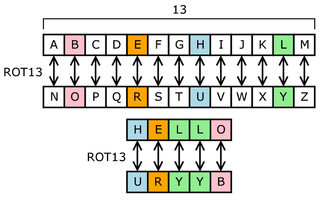
The rot13 operator implements a simple substitution
cipher that replaces each letter with the 13th letter after it
in the alphabet (mod 26):
This is the grammar for the Cipher language:
exp ::= string
| ( unary-op exp ) ; unary
| ( exp binary-op exp ) ; binary
| ( exp mixed-op number ) ; mixed
All values are strings. Numbers are literals in programs.
These are the operators I've defined thus far:
- unary :
rot13 - binary:
+ - mixed :
take,drop
Here is the evaluator working on the other examples from above:
> (value '("Hello, " + "Eugene"))
"Hello, Eugene"
> (value '("Eugene" take 3))
"Eug"
> (value '("Eugene" drop 4))
"ne"
I considered including a (exp in exp) expression, but
then we'd need boolean values, too. Let's keep things simple for
a one-day excursion.
Let's examine the Cipher interpreter, value.
Syntax Procedures
My first job, before writing the interpreter itself, was to implement syntax procedures.
Look at the top of
the file,
including (exp?) and (unary?).
Quick Exercise: The mixed? Predicate
mixed?.
This function takes one argument, which can be any Racket value.
It returns true if that value is a mixed Cipher expression, and
false otherwise. For example:
> (mixed? '("Hello, Eugene" take 3))
#t
> (mixed? '(("Hello" drop 1) take 3)) ; handles nested expressions
#t
> (mixed? 2) ; not a list
#f
> (mixed? '("Hello" drop)) ; list not long emough
#f
> (mixed? '("Hello, Eugene" drop "3")) ; second arg not a number
#f
> (mixed? '("Hello, Eugene" slice 3)) ; not a valid operator
#f
You may assume that I have already implemented the general type
predicate exp?.
Interpreter, Version 1.1
Take quick look at the rest of the syntax procedures:
- type predicates
- accessors
- constructors
Note: These functions have no knowledge of the meaning of the language. They know only about the syntax.
Now let's implement (value exp).
I have at least two options for writing the function:
-
Evaluate each kind of expression directly in
value. This is sometimes called inline code. - Write helper functions for each kind of expression.
Why did I choose helpers? The code is already complex enough, and as I add features to the language, the function will get even bigger. A monolithic function will be hard to read and hard to modify.
A compound example such as
(("abc" drop 2) + ("abc" take 2))
reminds us that we must evaluate any parts that are also
expressions.
Quick Exercise: The eval-mixed Function
value. The
function named eval-mixed takes three arguments: a
Cipher operator (a symbol), a string, and a number. The operator
will be 'take or 'drop.
$ (eval-mixed 'take "Eugene" 3) "Eug" $ (eval-mixed 'drop "Eugene" 3) "ene"You will want to use the Racket primitive
(substring string start end),
and probably (string-length string).
Interpreter, Version 1.2
Let's look more at value and its helpers:
I could implement the one-operator functions without a
cond expression, but using one...
- ... makes the code consistent: take/drop.
- ... makes the code easier to extend when we add new ops.
There are many options for implementing the helper functions:
- inline (what I did here)
- with more focused helper functions
- with an association list (save this for later)
How to implement rot13: with a look-up table, or with math?
Once I had a working evaluator, I wanted to test and play more.
Having to call value each time and quote the Cipher
program became annoying. So I implemented a REPL for Cipher,
based on
a Session 2 reading:
- I used
displayln, for the formatting. - But now I want a prompt.
- And a way to EXIT gracefully.
Adding a New Feature to Cipher—and the Interpreter
Option 1: Adding the Ability to Shift Strings
When doing this sort of string manipulation, we often want to shift strings like this:
"Eugene" → "neEuge" "abc" → "cab"
We can do this now in Cipher using a compound expression:
(("Eugene" drop 4) + ("Eugene" take 4))
(("abc" drop 2) + ("abc" take 2))
If we want to do this a lot, though, it would be nice if Cipher made it easier.
One way waould be let users of Cipher write a function named
shift and call it to perform this operation.
To do this, the Cipher evaluator would have to handle function definitions and function calls. We would have to extend the language grammar, and the interpreter, in several ways. That's too much work for a one-day excursion.
Another option would be to add a new operator to the
language, (exp shift num).
Practice for home: Do it.
Implementing shift directly repeats other code in the
interpreter. This is wasteful and prone to error. Many languages,
including C++ and Racket, avoid this problem with a preprocessor.
We could do the same thing in Cipher: have the evaluator
translate a shift expression into the equivalent Cipher
expression using take, drop, and
+ primitives, and then use existing machinery
to evaluate it.
This is a powerful idea. We study it in detail in the next unit of the course, "Syntactic Abstraction". At that point, we can add a 'shift' operator to Cipher as an example.
Option 2: Adding Local Variables
Instead, let's add a simpler extension: names for primitive values,
such as FIRST = "eugene" and
LAST = "wallingford". (This is similar to how
pi is a primitive value in Racket.)
To do this, we have to add variable references to grammar and update the other syntax procedures to work with them. We also need the ability to look up the value associated with a name.
That last part, you can do...
Quick Exercise: A lookup Function
(lookup sym lop), where lop is a list of
symbol/value pairs.
$ (lookup 'w '((e . "Eugene") (w . "Wallingford"))) "Wallingford" $ (lookup 's '((e . "Eugene") (w . "Wallingford"))) [error]
If you'd like to see recursive solution, check out this file.
Bonus Section: Interpreter, Version 2
We do not cover this session in class. Feel free to read it and the code, if you'd like. No worries, though: nothing in this section will be on the quiz.
To add primitive variable references to Cipher, we need a new idea for our interpreter: the idea of an environment. An environment is a data structure that associates names with values. We then use a lookup function to find a value given a name.
Implementation of the environment: a list of symbol/string pairs.
I also use a new-to-us primitive Racket function:
assoc.
We have to make some changes to the value function:
- add a new case to evaluate a variable reference
-
... which requires pass an environment to
value, on both the first call and all recursive calls -
... which changes the signature of the function, so we have to
make
valuean interface procedure to call a recursive helper function - now, we can have
valuevalidate the exp first
With these changes, Cipher supports named values.
- Here, we use them for global variables.
- We can use the same mechanism to implement local variables, which we also study in the next unit — finally!
- We can also use this same mechanism when we implement function calls! We will make that connection in the final unit of the course, "Data Abstraction".
Wrap Up
-
Reading
- Begin to review the lecture notes for Sessions 8-14.
- If you'd like a little more practice with mutual recursion, read this short demonstration of how to annotate an s-list. It gives you another example of how to use mutual recursion to process a 2-part data type — and more programming practice, if you like! This is a tougher problem than we've solved thus far, but will be able to follow the reading, even if you don't think you could write the function yourself.
-
Homework
- Homework 6 is available and due on Monday. It is a practice session for ...
-
Quiz
- Quiz 2 is one week from today.
- On Tuesday, we will have a review and practice session for the quiz. As you review, email me any questions you have, and I will try to answer them during the session.