October 30, 2010 1:01 PM
The Time is Right for Functional Design Patterns
Back in 1998, I documented some of the ideas that I used to teach functional programming in Scheme. The result was the beginnings of a small pattern language I called Roundabout. When I workshopped this paper at PLoP, I had a lot of fun, but it was a challenge. My workshop consisted of professional developers, most working in Java, with little or no experience in Scheme. Worse, many had been exposed to Lisp as undergraduates and had had negative experiences. Even though they all seemed open to my paper, subconsciously their eyes and ears were closed.
We gathered over lunch so that I could teach a quick primer on how to read Scheme. The workshop went well, and I received much useful feedback.
Still, that wasn't the audience for Roundabout. They were are OO programmers. To the extent they were looking for patterns to use, they were looking for GoF-style OO patterns, C++, Java, and enterprise patterns. I had a hard time finding an audience for Roundabout. Most folks in the OO world weren't ready yet; they were still trying to learn how to do OOD and OOP really well. I gave a short talk on how I use Roundabout in class at an ICFP workshop, but the folks there already knew these patterns well, and most were beyond the novice level at which they live. Besides, the functional programming world wasn't all that keen on the idea of patterns at all, not patterns in the style of Christopher Alexander.
Fast forward to 2010. We now have Scala and Clojure on the JVM. A local developer I know is working hard to wrap his head around FP. Last week, he sent me a link to an InfoQ talk by Aino Corry on Functional Design Patterns. The talk is about patterns more generally, what they are and how GoF patterns fit in the functional programming world. At about the 19:00 mark, she mentions... Roundabout! My colleague is surprised to hear my name and tweets his excitement.
My work on functional design patterns is resurfacing. Why? The world is changing. With Scala and Clojure poised to make noise in the Java enterprise world, functional programming is here. People are talking about Scheme and especially Haskell again. Functional programming is trendy now, with famous OO consultants talking it up and making the rounds at conferences and workshops giving talks about how important it is. (Some folks have been saying that for a while...)
The software patterns "movement" grew out of a need felt by many programmers around the world to learn how to do OO design and programming. Most had been weaned on traditional procedural programming and built up years of experience programming in that style, only to find that their experience didn't transfer smoothly into the OO world. Patterns were an ideal vehicle for documenting OO expertise and communicating it to programmers as they learned the new style.
We now face a similar transition in industry and even academia, as languages like Scala and Clojure begin to change how professionals build their systems. They are again finding that their experience -- now with OO -- does not transfer into the functional world without a few hitches. What we need now are papers that document functional design and programming patterns, both at the most basic level (like Roundabout) and at a higher level (like GoF). We have some starting points from which to begin the journey. There has been some good work done on refactoring functional-style programs, and refactoring is a complement to patterns.
This is a great opportunity for experienced functional programmers to teach their style to a large new audience that now has incentive to learn it. This is also a great opportunity to demonstrate again the value of the software pattern as a form for documenting and teaching how to build things. The question is, what to do next.
October 28, 2010 4:27 PM
Ideas, Execution, and Technical Achievement
Four or five years ago, my best buddy on campus and I were having lunch at our favorite Chinese buffet. He looked up between bites of General Tsao's and asked, "Why didn't you and I sit down five years ago and write Facebook?"
You see, he is an awesome programmer and has worked with me enough to know that I do all right myself. At various times, both of us have implemented bits and pieces of the technology that makes up Facebook. It doesn't look like all that big a deal.
I answered, "Because we didn't think of it."
The technical details may or may not have been a big deal. Once implemented, they look straightforward. In any case, though, the real reason was that it never occurred to us to write Facebook. We were techies who got along nicely with the tools available to us in 1999 or 2000, such as e-mail, wiki, and the web. If we needed to improve our experience, we did so by improving our tools. Driven by one of his own itches, Troy had done his M.S. research with me as his advisor, writing a Bayesian filter to detect spam. But neither of us thought about supplanting e-mail with a new medium.
We had the technical skills we needed to write Facebook. We just didn't have the idea of Facebook. Turns out, that matters.
That lunch conversation comes into my mind every so often. It came back yesterday when I read Philip Greenspun's blog entry on The Social Network. Greenspun wrote one of my favorite books, Philip and Alex's Guide to Web Publishing, which appeared in 1998 and which describes in great detail (and with beautiful photos) how to implement web community software. When his students ask how he feels about Zuckerberg getting rich without creating anything "new", Greenspun gives a wonderfully respectful and dispassionate answer: "I didn't envision every element of Facebook." Then he explains what he means.
Technically, Greenspun was positioned as well or better than my buddy and I to write Facebook. But he didn't the idea, either, at least not to the same level as Zuckerberg. Having the core of an idea is one thing. Developing it to the point that it becomes a platform that changes the world in which it lives is another. Turns out, that matters, too.
I like Lawrence Lessig's most succinct summation of what makes Zuckerberg writing Facebook a notable achievement: He did it. He didn't just have an idea, or talk about it, or dream about it. He implemented it.
That's what great hackers do.
Watch this short video to hear Zuckerberg himself say why he built. His answer is also central to the hacker ethic: Because he wanted to.
(Also read through to the end of Lessig's article for a key point that many people miss when they think about the success and achievement of things like Facebook and Twitter and Napster: The real story is not the invention.
Zuckerberg may or may not be a genius? I don't know or care. That is a word that modern culture throws around far too carelessly these days. I will say this. I don't think that creating Facebook is in itself sufficient evidence for concluding so. A lot of people have cool ideas. A more select group of people write the code to make their ideas come alive. Those people are hackers. Zuckerberg is clearly a great hacker.
I'm not a big Facebook user, but it has been on my mind more than usual the last couple of days. Yesterday was my birthday, and I was overwhelmed by all the messages I received from Facebook friends wishing me a happy day. They came from all corners of the country; from old grade-school friends I haven't seen in over thirty years; from high school and college friends; from professional friends and acquaintances. These people all took the time to type a few words of encouragement to someone hundreds of miles away in the middle of the Midwest. I felt privileged and a little humbled.
Clearly, this tool has made the world a different place. The power of the social network lies in the people. The technology merely enables the communication. That's a significant accomplishment, even if most of the effects are beyond what the creator imagined. That's the power of a good idea.
~~~~
All those years ago, my buddy and I talked about how little technical innovation there was in Facebook. Greenspun's answer reminds us that there was some. I think there is another element to consider, something that was a driving force at StrangeLoop: big data. The most impressive technical achievement of Facebook and smaller web platforms such as Twitter is the scale at which they operate. They've long ago outgrown naive implementations and have had to try to offer uninterrupted service in the face of massive numbers of users and exponential growth. Solving the problems associated with operating at such a scale is an ongoing technical challenge and a laudable achievement in its own right.
October 26, 2010 4:58 PM
Mindset, Faith, and Code Retreats
If I were more honest with myself, I would probably have to say something like this more often:
He also gave me the white book, XP Explained, which I dismissed outright as rubbish. The ideas did not fit my mental model and therefore they were crap.
Like many people, I am too prone to impose my way of thinking and working on everything. Learning requires changing how I think and do, and that can only happen when I don't dismiss new ideas as wrong.
I found that passage in Corey's Code Retreat, a review of a code retreat conducted by Corey Haines. The article closes with the author's assessment of what he had learned over the course of the day, including this gem:
... faith is a necessary component of design ...
This is one of the hardest things for beginning programmers to understand, and that gets in the way of their learning. Without much experience writing code, they often are overwhelmed by the uncertainty that comes with making anything that is just beyond their experience. And that is where the most interesting work lies: just beyond our experience.
Runners training for their first marathon often feel the same way. But experience is no antidote for this affliction. Despair and anger are common emotions, and they sometimes strike us hardest when we know how to solve problems in one way and are asked to learn a new way to think and do.
Some people are naturally optimistic and open to learning. Others have cultivated an attitude of openness. Either way, a person is better prepared to have faith that they will eventually get it. Once we have experience, our faith is buttressed by our knowledge that we probably will reach a good design -- and that, if we don't, we will know how to respond.
This article testifies to the power of a reflective code retreat led by a master. After reading it, I want to attend one! I think this would be a great thing for our local software community to try. For example, a code retreat could help professional programmers grok functional programming better than just reading books about FP or about the latest programming language.
~~~~
The article also opens with a definition of engineering I had not seen before:
... the strategy for causing the best change in a poorly understood situation within the available resources ...
I will think about it some more, but on first and second readings, I like this.
October 25, 2010 4:50 PM
A Programming Digression: Farey Sequences

Last Wednesday, I saw John Cook's article on rational approximations using Farey's algorithm, and it led me on a programming journey. You might find it entertaining.
First, some background. The students in my compilers course are writing a compiler for a simple numerical language I call Klein. Klein is a minimal functional language inspired by Doug Baldwin's MinimL, designed to give compiler students experience with all the important issues in the course while not duplicating very much. The goal is that students be able to write a complete and correct compiler for the language from scratch in a semester. Among Klein's limitations are:
- Repetition is done with recursion. There are no loops.
- There are only two data types, integers and booleans.
- All binding of values to names is done via function calls. There are no local variables, no assignments statements, and no sequences.
- There is only one primitive function, print, that can be called only at the top of a function definition.
As you can imagine, it is difficult to find good, large problems for which we can write Klein programs. So I'm always on the look-out for numerical algorithms that can be implemented in Klein.
When I saw Cook's article and Python program, I got to thinking... Wouldn't this be a cool application for Klein?
Of course, I faced a few problems. Cook's program takes as arguments a real number in [0..1), r, and an integer N. It returns a fraction that is the rational number closest in value to r with a denominator that no bigger than N. Klein does not have floating-point values, so I would have to fake even the real value being approximated! Without assignment statements and sequences of statements, let alone Python's multiple assignments and multiple returns, I would have to convert the algorithm's loop to a set of functions for computing the individual components of the converging bounds. Finally, without floats again, I would also have to compare the bounding fractions to the faked real number as fractions.
Those are just the sort of challenges that intrigue a programmer. I spent a couple of hours on Thursday slowly refactoring Cook's code to a Klein-like subset of Python. Instead of passing r to the main function, I fake it by passing in two arguments: the digits to the right of the decimal point as an integer, and a power of 10 to indicate its magnitude. These serve as numerator and denominator of a rational approximation, albeit with a very denominator. For example, r = 0.763548745, I pass in 7635487 and 10,000,000. The third argument to the function is N. Here is an example:
>>> farey( 127, 1000, 74)
8
63
8/63 is the best rational approximation for 0.127 with a denominator ≤ 74. My code prints the 8 and returns the 63, because that is best way for an equivalent Klein program to work.
Here is Cook's example of 1/e with a denominator bounded by 100:
>>> farey( 367879, 1000000, 100 )
32
87
Take a look at my Python code if you are easily amused. In one part of the program, I duplicated code with only small changes to the resulting functions, farey_num() andfarey_den. In another section, I avoided creating duplicate functions by adding a selector argument that I allowed me to use one bit of code for two different calculations. while_loop_for returns the next value for one of a, b, c, and d, depending on the value of its first argument. For some reason, I am fond of the code that replaces Cook's mediant variable.
At this point, the port to Klein was straightforward.
In the end, there is so much code to do what is basically a simple task: to compute row N of this tree on an as-needed basis, in the service of a binary search:

Programming in Klein feels a lot like programming in an integer assembly language. That can be an interesting experience, but the real point of the language is to exercise students as they write a compiler. Still, I find myself now wanting to implement refactoring support for Klein, in order to make such digressions flow faster in the future!
I enjoyed this little diversion so much that I've been buttonholing every colleague who walks through the door. I decided I'd do the same to you.
October 21, 2010 4:45 PM
On Kazoos and Violins
Coming out of Strange Loop, I have been reading more about Scala and Clojure, both of which bring a lot of cool functional programming ideas to the JVM world. A lot of people have seem to have made deeper inroads into FP via Scala than via Clojure. That is certainly true among the companies in my area. That is not too surprising. Scala looks more like what they are used to than Clojure. It feels more comfortable.
This context is probably one of the reasons that I so liked this quote I read yesterday from Brenton Ashworth, a serial contributor to the Clojure community:
I'm now convinced that choosing a language based on how easy it is to read or write is a very bad idea. What if we chose musical instruments based on how easy they are to play? Everyone would playing kazoos. You can't think deeply about music if all you know is a kazoo.
This reminds me of a story Alan Kay often tells about violins. I have alluded to it at least once before:
And we always need to keep in mind the difference between essential and gratuitous complexity. I am often reminded of Alan Kay's story about learning to play violin. Of course it's hard to learn. But the payoff is huge.
New tools often challenge us, because knowing them well will change us. And such change is a part of progress. Imagine if no one had wanted to learn to fly an airplane because it was too different from driving a car or a horse.
Don't get me wrong: I am not comparing Scala to a kazoo and Clojure to a violin! I don't know either language well enough to make grand pronouncements about them, but my small bit of study tells me that both are powerful, valuable languages, languages worth knowing. I'm simply concerned that too many people opt out of learning Clojure well because of how it looks. As Ashworth says in the sentence immediately following the passage quoted above, "Skill at reading and writing code is learned."
You can do it! Don't settle on something only because something else looks unfamiliar. By taking the easier path in this moment, you may be making your path harder in the long run.
October 21, 2010 8:50 AM
Strange Loop Redux

I am back home from St. Louis and Des Moines, up to my next in regular life. I recorded some of my thoughts and experiences from Strange Loop in a set of entries here:
- Day 1
- Day 2
- Miscellany
Unlike most of the academic conferences I attend, Strange Loop was not held in a convention center or in a massive conference hotel. The primary venue for the conference was the Pageant Theater, a concert nightclub in the Delmar Loop:

This setting gave the conference's keynotes something of an edgy feel. The main conference lodging was the boutique Moonrise Hotel a couple of doors down:

Conference session were also held in the Moonrise and in the Regional Arts Commission building across the street. The meeting rooms in the Moonrise and the RAC were ordinary, but I liked being in human-scale buildings that had some life to them. It was a refreshing change from my usual conference venues.
It's hard to summarize the conference in only a few words, other than perhaps to say, "Two thumbs up!" I do think, though, that one of the subliminal messages in Guy Steele's keynote is also a subliminal message of the conference. Steele talked for half an hour about a couple of his old programs and all of his machinations twenty-five or forty years to make them run in the limited computing environments of those days. As he went to all the effort to reconstruct the laborious effort that went into those programs in the first place, the viewer can't help but feel that the joke's on him. He was programming in the Stone Age!
But then he gets to the meat of his talk and shows us that how we program now is the relic of a passing age. For all the advances we have made, we still write code that transitions from state to state to state, one command at a time, just like our cave-dwelling ancestors in the 1950s.
It turns out that the joke is on us.
The talks and conversations at Strange Loop were evidence that one relatively small group of programmers in the midwestern US are ready to move into the future.
October 20, 2010 12:33 PM
Because 26.3 Miles Would Be Crazy

I awoke Sunday to a beautiful, sunny, crisp October morning, not sure of what to expect.
My training for the Des Moines Marathon had begun back in July, and it had been full of ups and downs. My mileage had been reasonably steady, after one down week at the end of July, but I'd never developed much "long speed". Long runs were slow when they went well and tough when they didn't. I had a goal in my mind -- 8:36 miles -- but had no concrete evidence that I was ready to achieve it.
I arrived downtown later than I had been planning. This could have been a bad thing, an opportunity to start worrying about all that was going to go wrong. Instead, I chose to do something I'd never done at a race before: make a conscious effort to think positively. Don't worry about Mile 23, or my 10K split, or whether my pace at the halfway point is fast enough for me to PR. The best way to run the race was to just keep running. It is a cliché, I know, but I decided to take the race one mile at a time.
This year, Des Moines drew over 1600 marathoners, along with many, many more half-marathoners. For us runners, that meant a crowded start. When the gun sounded to begin the race, those of us back in the chute could only wait for an opportunity to start moving. When we did, moving was slow. It took a couple of minutes to reach the starting line (thank you for chip timing!) and several more minutes to break free enough to run full stride. While this put me behind my target pace from the outset, it also kept me calm and under control.
Just before the 3-mile mark, the marathoners and half-marathoners split off onto different routes. A helpful spectator made sure we knew which way to go:
 |
It turns out, marathoners are insane.
I held steady in my plan to just run. As I reached each mile marker, I clicked my watch and said to myself, "just another mile", in honor of the mile I had just completed. I didn't want to think about the fact that I had already run 8 miles, or that I still had 15 miles to go. I had just run another mile -- good for me. I looked at my watch to see how fast I had run that mile, in order that I could make an adjustment if necessary for the new mile I was beginning.
This was so different from my usual practice. I had no long-term plan, and I paid no attention to my splits beyond the single mile. Throughout the race, I rarely knew how long I had been running overall, and I never knew my average pace. Just another mile.

Around the 11-mile mark, I noticed that my legs felt heavy. That wasn't unexpected; they had felt heavy through my taper. But I was running strong, so I didn't worry too much. Soon, we entered Drake Stadium, site of the nationally-renowned Drake Relays. There, we ran one lap on its blue track, which has hosted national and international stars, and passed the 12-mile mark of the race. I forgot about my legs.
As the race wore on, I added two elements to my "positive thinking" regimen. First, I decided to smile more. That's not my natural state, so doing so involves some conscious thought. Second, I tried to thank as many people as I could along the way. When I passed a police officer holding back traffic, I said, "Thank you". I waved to the bands playing for us and thanked spectators who cheered us on. Having gratitude at the forefront of my mind did wonders for my mood.
Marathon signage can be a great source of distraction and inspiration. On this day I didn't notice as many, but then I was mostly focused on the mile I was currently running. I did see a helpful T-shirt early in the marathon. It was a quote from Paul Tergat, a top marathoner and former world-record holder:
Ask yourself:
Can I give more?
The answer is usually yes.
This quote stayed in my mind. As the race wore on, I knew that it would come in handy.
When I reached the Mile 24 marker, I asked myself, "Can I give more?" The answer was yes -- at least until we reached a steady incline leading up to a bridge. About that time, a fast runner passed us -- he must have been a pacer catcher up with his group -- and said, "You can do it. This is the last hill, and then it will be flat and downhill to the end." I thanked him for the good news and gave a little more.

Then came the sign for Mile 25. Just another mile. I recalled a long run from a couple of months ago that had prepared me for exactly this moment. "Can I give more?" Well, I can keep on pushing.
The Mile 26 marker seemed to take forever to arrive. When it did, I had more to give, so I gave what was left. I did not run especially fast over the last 1.2 miles, but I ran hard, strong, and at a pace I was proud of. I crossed the line as strong as I have ever finished a marathon, with the crowd cheering me and with a smile on my face.
I looked at my watch: 3:45:55. By all rights, I could have been disheartened... My marathon PR is 3:45:15, set in Des Moines six years ago. To work so hard, run so smart, and finish a mere forty-one seconds off of a new personal best! What about the slow first mile because I started too far back in the pack? Or the restroom break of over a minutes in the fifteenth mile?
But there are no "what if?"s. After the last four years of off-and-on-again illness, with so many interruptions to my running, I was quite happy to finish strong, to feel good, to produce a race and a time that I can remember proudly.
One other sign along the course made me laugh:
Because 26.3 miles would be crazy
That about says it all.
October 16, 2010 7:59 PM
Strange Loop This and That
Some miscellaneous thoughts after a couple of days in the mix...
Pertaining to Knowing and Doing
** Within the recurring theme of big data, I still have a few things to study: MongoDB, CouchDB, and FlockDB. I also learned about Pig, a language I'd never heard of before. I think I need to learn it.
** I need to be sure that my students learn about the idea of multimethods. Clojure has brought them back into mainstream discussion.
** Kevin Weil, who spoke about NoSQL at Twitter, told us that his background is math and physics. Not CS. Yet another big-time developer who came to programming from another domain because they had real problems to solve.
Pertaining to the Conference
** The conference served soda all day long, from 8:00 in the morning to the end of the day. Hurray! My only suggestion: add Diet Mountain Dew to the selections.
** The conference venues consist of two rooms in a hotel, two rooms in a small arts building, and the auditorium of the Pageant Theater. The restrooms are all small. During breaks, the line for the men's room was, um, long. The women in attendance came and went without concern. This is exactly opposite of what one typically sees out in public. The women of Strange Loop have their revenge!
** This is the first time I have ever attended a conference with two laptop batteries. And I saw that it was good. Now, I just have to find out why every couple of weeks my keyboard and trackpad freeze up and effectively lock me out. Please, let it not be a failing mother board...
Pertaining to Nothing But Me
** Like every conference, Strange Loop fills the silence between sessions with a music loop. The music the last two days has been aimed at its audience, which is mostly younger and mostly hipper than I am. I really enjoyed it. I even found a song that will enter my own rotation, "Hey, Julie" by Fountains of Wayne. You can, of course, listen to it on YouTube. I'll have to check out more Fountains of Wayne later.
** On Twitter, I follow a relatively small number of people, mostly professional colleagues who share interesting ideas and links. I also follow a few current and former students. Rounding out the set are a couple connections I made with techies through others, back when Twitter was small. I find that I enjoy their tweets even though I don't know them, or perhaps because I don't.
On Thursday, it occurred to me: Maybe it would be fun to follow some arbitrary incredibly popular person. During one of the sessions, we learned that Lady Gaga has about 6,500,000 followers, surpassing Ashton Kutcher's six million. I wonder it would be like to have their tweets flowing in a stream with those of Brian Marick and Kevlin Henney, Kent Beck and Michael Feathers.
October 16, 2010 9:09 AM
Strange Loop, Day 2 Afternoon
After eating some dandy deep-dish BBQ chicken at Pi Pizzeria with the guys from T8 Webware (thanks, Wade!), I returned for a last big run of sessions. I'll save the first session for last, because my report of it is the longest.
Android Squared
I went to this session because so many of my students want me to get down in the trenches with phone programming. I saw a few cool tools, especially RetroFit, a new open-source framework for Android. There are not enough hours in a day for me to explore every tool out there. Maybe I can have a student do an Android project.
Java Puzzlers
And I went to this session because I am weak. I am a sucker for silly programming puzzles, especially ones that take advantage of the dark corners of our programming languages. This session did not disappoint in this regard. Oh, the tortured code they showed us! I draw from this experience a two-part moral:
- Bad programmers can write really bad code, especially in a complex language.
- A language that is too complex makes bad programmers of us all.
Brian Marick on Outside-In TDD
Marick demoed a top-down | outside-in style of TDD in Clojure using Midje, his homebrew test package. This package and style make heavy use of mock objects. Though I've dinked around a bit in Scala, I've done almost nothing in Clojure, so I'll have to try this out. The best quote of the session echoed a truth about all programming: You should have no words in your test that are not specifically about the test.
Douglas Crockford, Open-Source Heretic
Maybe my brain was fried by the end of the two days, or perhaps I'm simply not clever enough. While I able to chuckle several times through this closing keynote, I never saw the big picture or the point of the talk. There were plenty of interesting, if disconnected, stories and anecdotes. I enjoyed Crockford's coverage of several historical mark-up languages, including Runoff and Scribe. (Runoff was the forebear of troff, a Unix utility I used throughout grad school -- I even produced my wedding invitations using it! Fans of Scribe should take a look at Scribble, a mark-up tool built-on top of Racket.) He also told an absolutely wonderful story about Grace Murray Hopper's A-0, the first compiler-like tool and likely the first open-source software project.
Panel on the Future of Languages
Panels like this often don't have a coherent summary. About all I can do is provide a couple of one-liners and short answers to a couple of particularly salient questions.
Joshua Bloch: Today's patterns are tomorrow's language features. Today's bugs are tomorrow's type system features.
Douglas Crockford: Javascript has become what Java was meant to be, the language that runs everywhere, the assembly language of the web.
Someone in the audience asked, "Are changes in programming languages driven by academic discovery or by practitioner pain?" Guy Steele gave the best answer: The evolution of ideas is driven by academics. Uptake is driven by practitioner needs.
So, what is the next big thing in programming languages? Some panelists gave answers grounded in today's problems: concurrency, a language that could provide and end-to-end solution for the web, and security. One panelists offered laziness. I think that laziness will change how many programmers think -- but only after functional programming has blanketed the mainstream. Collectively, several panelists offered variations of sloppy programming, citing as early examples Erlang's approach to error recovery, NoSQL's not-quite-data consistency, and Martin Rinard's work on acceptability-oriented computing.
The last question from the audience elicited some suggestions you might be able to use. What language, obscure or otherwise, should people learn in order to learn the language you really want them to learn? For this one, I'll give you a complete list of the answers:
- Io. (Bruce Tate)
- Rebol. (Douglas Crockford)
- Forth. Factor. (Alex Payne)
- Scheme. Assembly. (Josh Bloch)
- Clojure. Haskell. (Guy Steele)
I second all of these suggestions. I also second Steele's more complete answer: Learn any three languages you do not know. The comparisons and contrasts among them will teach you more than any one language can.
Panel moderator Ted Neward closed the session with a follow-up question: "But what should the Perl guys learn while they are waiting for Perl 6?" We are still waiting for the answer.
October 15, 2010 11:46 PM
Strange Loop, Day 2 Morning
Perhaps my brain is becoming overloaded, or I have been less disciplined in picking talks to attend, or the slate of sessions for Day 2 is less coherent than Day 1's. But today has felt scattered, and so far less satisfying than yesterday. Still, I have had some interesting thoughts.
Billy Newport on Enterprise NoSQL
This was yet another NoSQL talk, but not, because it was different than the preceding ones at the conference. This talk was not about any particular technologies. It was about mindsets.
Newport explained that NoSQL means not only SQL. These two general approaches to data storage offer complementary strengths and weaknesses. This means that they are best used in different contexts.
I don't do enough programming for big data apps to appreciate all the details of this talk. Actually, I understood most of the basic concepts, but they soon starting blurring in my mind, because I don't have personal experience on which to hang them. A few critical points stood out:
- In the SQL world, the database is the "system of record" for all data, so consistency is a given. In the NoSQL world, having multiple systems of record is normal. In order to ensure consistency, the application uses business rules to bring data back into sync. This requires a big mind shift for SQL guys.
- In the SQL world, the row is a bottleneck. In the NoSQL world, any node can handle the request. So there is not a bottleneck, which means the NoSQL approach scales transparently. J But see the first bullet.
These two issues are enough to see one of Newport's key points. The differences between the two worlds is not only technical but also cultural. SQL and NoSQL programmers use different vocabulary and have different goals. Consider that "in NoSQL, 'query' is a dirty word". NoSQL programmers do everything they can to turn queries into look-ups. For the SQL programmer, the query is a fundamental concept.
The really big idea I took away from this talk is that SQL and NoSQL solve different problems. The latter optimizes for one dominant question, while the former seeks to support an infinite number of questions. Most of the database challenges facing NoSQL shops boil down to this: "What happens if you ask a different question?"
Dean Wampler on Scala
The slot in which this tutorial ran was longer than the other sessions at the conference. This allowed Wampler to cover a lot of details about Scala. I didn't realize how much of an "all but the kitchen sink" language Scala is. It seems to include just about every programming language feature I know about, drawn from just about every programming language I know about.
I left the talk a bit sad. Scala contains so much. It performs so much syntactic magic, with so many implicit conversions and so many shortcuts. On the one hand, I fear that large Scala programs will overload programmers' minds the way C++ does. On the other, I worry that its emphasis on functional style will overload programmers' minds the way Haskell does.
October 15, 2010 12:34 PM
Guy Steele's Own Strange Loop
The last talk of the afternoon of Day 1 was a keynote by Guy Steele. My notes for his talk are not all that long, or at least weren't when I started writing. However, as I expected, Steele presented a powerful talk, and I want to be able to link directly to it later.
Steele opened with a story about a program he wrote forty years ago, which he called the ugliest program he ever wrote. It fit on a single punch card. To help us understand this program, he described in some detail the IBM hardware on which it ran. One problem he faced as a programmer is that the dumps were undifferentiated streams of bytes. Steele wanted line breaks, so he wrote an assembly language program to do that -- his ugliest program.
Forty years later, all he has is the punch card -- no source. Steele's story then turned into CSI: Mainframe. He painstakingly reverse-engineered his code from punches on the card. We learned about instruction format, data words, register codes... everything we needed to know how this program managed to dump memory with newlines and fit on a single card. The number of hacks he used, playing on puns between op codes and data and addresses, was stunning. That he could resurrect these memories forty years later was just as impressive.
I am just old enough to have programmed assembly for a couple of terms on punch cards. This talk brought back memories, even how you can recognize data tables on a card by the unused rows where there are no op codes. What a wonderful forensics story.
The young guys in the room liked the story, but I think some were ready for the meet of the talk. But Steele told another, about a program for computing sin 3x on a PDP-11. To write this program, Steele took advantage of changes in the assembly languages between the IBM mainframe and the PDP-11 to create more readable code. Still, he had to use several idioms to make it run quickly in the space available.
These stories are all about automating resource management, from octal code to assemblers on up to virtual memory and garbage collection. These techniques let the programmer release concerns about managing memory resources to tools. Steele's two stories demonstrate the kind of thinking that programmers had to do back in the days when managing memory was the programmer's job. It turns out that the best way to think about memory management is not to think about it at all.
At this point, Steele closed his own strange loop back to the title of his talk. His thesis is this: the best way to think about parallel programming is not to have to.
If we program using a new set of idioms, then parallelism can be automated in our tools. The idioms aren't about parallelism; they are more like functional programming patterns that commit the program less to underlying implementation.
There are several implications of Steele's thesis. Here are two:
- Accumulators are bad. Divide and conquer is good.
- Certain algebraic properties of our code are important. Programmers need to know and preserve them in then code they write.
Steele illustrated both of these implications by solving an example problem that would fit nicely in a CS1 course: finding all the words in a string. With such a simple problem, everyone in the room has an immediate intuition about how to solve it. And nearly everyone's intuition produces a program using accumulators that violates several important algebraic properties that our code might have.
One thing I love about Steele's talks: he grounds ideas in real code. He developed a complete solution to the problem in Fortress, the language Steele and his team have been creating at Sun/Oracle for the last few years. I won't try to reproduce the program or the process. I will say this much. One, the process demonstrated a wonderful interplay between functions and objects. Two, in the end, I felt like we had just used a process very similar to the one I use when teaching students to create this functional merge sort function:
(define mergesort
(lambda (lst)
(merge-all (map list lst))))
Steele closed his talk with the big ideas that his programs and stories embody. Among the important algebraic properties that programs should have whenever possible are ones we all learned in grade school, explicitly or implicitly. Though they may still sound scary, they all have intuitive common meanings:
- associative -- grouping don't matter
- commutative -- order doesn't matter
- idempotent -- duplicates don't matter
- identity -- this value doesn't matter
- zero -- other values don't matter
Steele said that "wiggle room" was the key buzzword to take away from his talk. Preserving invariants of these algebraic properties give the compiler wiggle room to choose among alternative ways to implement the solution. In particulars, associativity and commutativity give the compiler wiggle room to parallelize the implementation.
(Note that the merge-all operation in my mergesort program satisfies all five properties.)
One way to convert an imperative loop to a parallel solution is to think in terms of grouping and functions:
- Bunch mutable state together as a state "value".
- Look at the loop as an application of one or more state transformation functions.
- Look for an efficient way to compose these transformation functions into a single function.
The first two steps are relatively straightforward. The third step is the part that requires ingenuity!
In this style of programming, associative combining operators are a big deal. Creating new, more diverse associative combining operators is the future of programming. Creating new idioms -- the patterns of programs written in this style -- is one of our challenges. Good programming languages of the future will provide, encourage, and enforce invariants that give compilers wiggle room.
In closing, Steele summarized our task as this: We need to do for processor allocation what garbage collection did for memory allocation. This is essential in a world in which we have parallel computers of wildly different sizes. (Multicore processors, anyone?)
I told some of the guys at the conference that I go to hear Guy Steele irrespective of his topic. I've been fortunate enough to be in a small OOPSLA workshop on creativity with Steele, gang-writing poetry and Sudoku generators, and I have seen him speak a few times over the years. Like his past talks, this talk makes me think differently about programs. It also crystallizes several existing ideas in a way that clarifies important questions.
October 14, 2010 11:17 PM
Strange Loop 2010, Day 1 Afternoon
I came back from a lunchtime nap ready for more ideas.
You Already Use Closures in Ruby
This is one of the talks I chose for a specific personal reason. I was looking for ideas I might use in a Cedar Valley Tech Talk on functional programming later this month, and more generally in my programming languages course. I found one, a simple graphical notation for talking about closures as a combination code and environment. Something the speaker said about functions sharing state also gave me an idea for how to use the old koan on the dual "a closure is poor man's object / an object is poor man's closure".
NoSQL at Twitter
Speaker Kevin Weil started by decrying his own title. Twitter uses MySQL and relational databases everywhere. They use distributed data stores for applications that need specific performance attributes.
Weil traced Twitter's evolution toward different distributed data solutions. They started with Syslog for logging applications. It served there early needs but didn't scale well. They then moved to Scribe, which was created by the Facebook team to solve the same problem and then open-sourced.
This move led to a realization. Scribe solved Twitter's problem and opened new vistas. It made logging data so easy, that they started logging more. Having more data gave them better insight into the behavior of their users, behaviors they didn't even know to look for before. Now, data analytics is one of Twitter's most interesting areas.
The Scribe solution works, scaling with no changes to the architecture as data throughput doubles; they just add more servers. But this data creates a 'write' problem: giving today's takes technology, it takes something like 42 hours to write 12 TB to a single hard drive. This led Twitter to add Hadoop to its toolset. Hadoop is both scalable and powerful. Weil mentioned an a 4,000-node cluster at Yahoo! that had sorted one terabyte of integers in 62 seconds.
The rest of Weil's talk focused on data analytics. The key point underlying all he said was this: It is easy to answer questions. It is hard to ask the right questions. This makes experimental programming valuable, and by extension a powerful scripting language and short turnaround times. They need time to ask a lot of questions, looking for good ones and refining promising questions into more useful ones. Hadoop is a Java platform, which doesn't fit those needs.
So, Twitter added Pig, a high-level language that sits atop Hadoop. Programs written in Pig are easy to read and almost English-like. Equivalent SQL programs would probably be shorter, but Pig compiles to MapReduce jobs that run directly on Hadoop. Pig extracts a performance penalty, but the Twitter team doesn't mind. Weil captured why in another pithy sentence: I don't mind if a 10-minute job runs in 12 minutes if it took me 10 minutes to write the script instead of an hour.
Twitter works on several kinds of data-analytic problems. A couple stood out:
- correlating big data. How do different kinds of user behave -- mobile, web, 3rd-party clients? What features hook users? How do user cohorts work? What technical details go wrong at the same time, leading to site problems?
- research on big data. What can we learn from a users' tweets, the tweets of those they follow, or the tweets of those who follow them? What can we learn from asymmetric follow relationships about social and personal interests?
As much as Weil had already described, there was more! HBase, Cassandra, FlockDB, .... Big data means big problems and big opportunities, which lead to hybrid solutions that optimize competing forces. Interesting stuff.
Solutions to the Expression Problem
This talk was about Clojure, which interests me for obvious reasons, but the real reason I chose this talk was that I wanted to know what is the expression problem! Like many in the room, I had experienced the expression problem without knowing it by this name:
The Expression Problem is a new name for an old problem. The goal is to define a datatype by cases, where one can add new cases to the datatype and new functions over the datatype, without recompiling existing code, and while retaining static type safety (e.g., no casts).
Speaker Chris Houser used an example in which we need to add a behavior to an existing class that is hard or impossible to modify. He then stepped through four possible solutions: the adapter pattern and monkey patching, which are available in languages like Java and Ruby, and multimethods and protocols, which are available in Clojure.
I liked two things about this talk. First, he taught his a "failure-driven" way: pose a problem, solve it using a known technique, expose a weakness, and move on to a more effective solution. I often use this technique when teaching design patterns. Second, the breadth of the problem and its potential solutions encouraged language geeks to talk ideas in language design. The conversation included not only Java and Clojure but also Javascript, C#, and macros.
Guy Steele
My notes on this talk aren't that long, but it was important enough to have its own entry. Besides, this entry is already long enough!
October 14, 2010 10:02 PM
Strange Loop 2010, Day 1 Morning
I arrived in the University City district this morning ready for a different kind of conference. The program is an interesting mix of hot topics in technology, programming languages, and computing. My heuristic for selecting talks to attend was this: Of the talks in each time slot, which discusses the biggest idea I need to know more about? The only exceptions will be talks that fill a specific personal need, in teaching, research, or personal connections.
A common theme among the talks I attended today was big data. Here are some numbers I jotted down. They may be out of date by now, or I may have made an error in some of the details, but the orders of magnitude are impressive:
- Hilary Mason reported that bit.ly processes 10s of millions URLs per day, 100s of millions of events per day, and 1,000s of millions data points each day.
- Google processes 24 petabytes a day, which amounts to 8 exabytes a year.
- Digg has a 3 terabyte Cassandra database. This is dwarfed by Facebook's 150-node Cassandra cluster that comprises 150 terabytes.
- Twitter users generate 12 terabytes of data each day -- the equivalent of 17,000 CDs -- and more than 4 petabytes each year. Also astounding: the data rate is doubling multiple times a year.
All of these numbers speak to the need for more CS programs to introduce students to data-intensive computing.
Hilary Mason on Machine Learning
Mason is a data scientist at bit.ly, a company that faces "wicked hard problems" at scale. These problems arise from the combination of algorithms, on-demand computing, and "data, data, data". Mason gave an introduction to machine learning as applied to some of these problems. She had a few quotable lines:
- AI was "founded on a remarkable conceit". This reminded me of a recent entry.
- "Academics like to create new terms, because if they catch on the academics get prizes."
- "Only a Bayesian can tell you why if there's a 50-50 chance that something will happen, then 90% of the time it will."
She also sprinkled her top with programming tips. One of the coolest was that you can append a "+" to the end of any bit.ly URL to get analytic metrics for it.
Gradle
I had planned to go to a talk on Flickr's architecture, but I talked so long in the break that the room full before I got there. So I stopped in on a talk by Ken Sipe on Gradle, a scriptable Java build system built on top of Groovy. He had one very nice quote as well: "I can't think of a real use of this idea. I just like showing it off." The teacher and hacker in me smiled.
Eben Hewitt on Adopting Cassandra
Even if you are not Google, you may have to process a lot of data. Hewitt talked about some of the efforts made to scale relational databases to handle big data (query tuning, indexes, vertical scaling, shards, and denormalization). This sequence of fixes made me think of epicycles, fixes applied to orbits of heavenly bodies in an effort to match observed data. At some point, you start looking for a theory that fits better up front.
That's what happened in the computing world, too. Soon there were a number of data systems defined mostly by what they are not: "NoSQL". That idea is not new. Lotus Notes used a document-oriented storage system; Smalltalk images store universes of objects. Now, as the problem of big data becomes more prevalent, new and different implementations have been proposed.
Hewitt talked about Cassandra and what distinguishes it from other approaches. He called Cassandra the love child of the Google BigTable paper (2006) and the Amazon Dynamo paper (2007). He also pointed out some of the limitations that circumscribe its applicability. In the NoSQL approaches, there is "no free lunch": you give up many relational DB advantages, such as transactions, joins, and ad hoc queries.
He did advocates one idea I'll need to read more about: that we should shift our attention from the CAP theorem of distributed data systems, which is useful but misses some important dynamic distinctions, with Abadi's PACELC model: If the data store is Partitioned, then you trade off between Availability and Consistency; Else you trade off between Latency and Consistency.
October 13, 2010 10:20 PM
Serendipitous Connections
I'm in St. Louis now for Strange Loop, looking at the program and planning my schedule for the next two days. The abundant options nearly paralyze me... There are so many things I don't know, and so many chances to learn. But there are a limited number of time slots in any day, so the chances overlap.
I had planned to check in at the conference and then eat at The Pasta House, a local pasta chain that my family discovered when we were here in March. (I am carbo loading for the second half of my travels this week.) But after I got the motel, I was tired from the drive and did not relish getting into my car again to battle the traffic again. So I walked down the block to Bartolino's Osteria, a more upscale Italian restaurant. I was not disappointed; the petto di pollo modiga was exquisite. I'll hit the Pasta House tomorrow.
When I visit big cities, I immediately confront the fact that I am, or have become, a small-town guy. Evening traffic in St. Louis overwhelms my senses and saps my energy. I enjoy conferences and vacations in big cities, but when they end I am happy to return home.
That said, I understand some of the advantages to be found in large cities. Over the last few weeks, many people have posted this YouTube video of Steven Johnson introducing his book, "Where Good Ideas Come From". Megan McArdle's review of the book points out one of the advantages that rises out of all that traffic: lots of people mean lots of interactions:
... the adjacent possible explains why cities foster much more innovation than small towns: Cities abound with serendipitous connections. Industries, he says, may tend to cluster for the same reason. A lone company in the middle of nowhere has only the mental resources of its employees to fall back on. When there are hundreds of companies around, with workers more likely to change jobs, ideas can cross-fertilize.
This is one of the most powerful motivations for companies and state and local governments in Iowa to work together to grow a more robust IT industry. Much of the focus has been on Des Moines, the state capitol and easily the largest metro area in the state, and on the Cedar Rapids/Iowa City corridor, which connects our second largest metro area with our biggest research university. Those areas are both home to our biggest IT companies and also home to a lot of people.
The best IT companies and divisions in those regions are already quite strong, but they will be made stronger by more competition, because that competition will bring more, and more diverse, people into the mix. These people will have more, and more diverse, ideas, and the larger system will create more opportunities for these ideas to bounce off one another. Occasionally, they'll conjoin to make something special.
The challenge of the adjacent possible makes me even more impressed by start-ups in my small town. People like Wade Arnold at T8 Webware are working hard to build creative programming and design shops in a city without many people. They rely on creating their own connections, at places like Strange Loop all across the country. In many ways, Wade has to think of his company as an incubator for ideas and a cultivator of people. Whereas companies in Des Moines can seek a middle ground -- large enough to support the adjacent possible but small enough to be comfortable -- companies like T8 must create the adjacent possible in any way they can.
October 10, 2010 10:55 AM
Teachers Need Relational Understanding
Last week I was pointed in the direction of Richard Skemp's 1976 article, Relational Understanding and Instrumental Understanding, on how peoples' different senses of the word "understanding" can create dissonance in learning. Relational understanding is what most of us usually mean by understanding: knowing how to solve a problem and knowing on a deeper level why that works and how it relates to the fundamental ideas of the domain. Sometimes, though, we settle for instrumental understanding, simply knowing the rules that enable us to solve a problem. Skemp describes the cognitive mismatch that occurs when a teacher is thinking in terms of one kind of understanding and the student in terms of the other. Throw in a textbook that aims at one or the other, and it's no wonder that teachers and students sometimes have a difficult time working together.
The paper is a little long for its message, but Skemp does try to cover a lot of ground in his own slow realization that teachers need to see this dissonance as a concrete challenge to their efforts to help students learn. He even considers the sort of situations in which a teacher may have to settle for giving students an instrumental understanding of a topic. But one thing is clear:
... nothing else but relational understanding can ever be adequate for a teacher.
I know that when I am weakest as a teacher, it is either because I am underprepared for a particular lesson or because my understanding of a topic is instrumental at best.
I often hear teachers at all levels talk about teaching a new course by staying one chapter ahead of the students in the textbook. While there may situations in which this approach is unavoidable, it is always less than ideal, and any teacher who does it is almost necessarily shortchanges the students. Teaching is so much more than presenting facts, and if all the teacher knows today is the facts his or her students will be seeing a week or so hence, there is no way that student learning can tie ideas together or push beyond 'how' to 'why'.
When I think about teaching computer science and especially programming, I think of three levels of activity that give me different levels of understanding:
- reading about something, even extensively
- doing something, applying knowledge in practice
- understanding something at a deeper level
At the third level, I know not only how to solve problems, but when and how to break the rules, and when and how to reason from first principles to create a new method of attack. When I am at my best as a teacher, I feel fluid in the classroom, knowing that my deep understanding of an area has prepared me for nearly any situation I might encounter.
I'll close with this quote from Skemp, which alone was worth reading the paper for:
... there are two kinds of simplicity: that of naivety; and that which, by penetrating beyond superficial differences, brings simplicity by unifying.
Many people talk about the virtue of simplicity, but this sentence captures in fewer than two dozen words two very different senses of the word and expresses that the best kind of simplicity both grasps differences and unifies over them.
That is what relational understanding is about.
October 08, 2010 3:53 PM
Strange Loops
As busy as things are here with class and department duties, I am excited to be heading to StrangeLoop 2010 next week. The conference description sounds like it is right up my alley:
Strange Loop is a developer-run software conference. Innovation, creativity, and the future happen in the magical nexus "between" established areas. Strange Loop eagerly promotes a mix of languages and technologies in this nexus, bringing together the worlds of bleeding edge technology, enterprise systems, and academic research.
Of particular interest are new directions in data storage, alternative languages, concurrent and distributed systems, front-end web, semantic web, and mobile apps.
One of the reasons I've always liked OOPSLA is that it is about programming. It also mixes hard-core developers with academics, tools with theory. Unfortunately, I'll be missing OOPSLA (now called SPLASH) again this year. I hope that StrangeLoop will inspire me in a similar way. The range of technologies and speakers on the program tells me it probably will.
The day after I return from St. Louis, I hit the road again for the Des Moines Marathon, where I'll run strange loops of a different sort. My training has gone pretty well since the end of July, with mileage and speed work hitting targets I set back in June. Before my taper, I managed three weeks of 50 miles or more, including three 20+ mile long runs. Will that translate into a good race day? We never know. But I'm looking forward to the race, as well as the Saturday expo and dinner with a good buddy the night before.
If nothing else, the marathon will give me a few hours to reflect on what I learn at StrangeLoop and to think about what I will do with it!
October 06, 2010 11:24 AM
Studying Program Repositories

Last week, Garrett Morris presented an experience report at the 2010 Haskell Symposium entitled Using Hackage to Inform Language Design, which is also available at Morris's website. Hackage is an online repository for the Haskell programming community. Morris describes how he and his team studied programs in the Hackage repository to see how Haskell programmers work with a type-system concept known as overlapping instances. The details of this idea aren't essential to this entry, but if you'd like to learn more, check out Section 6.2.3 in this user guide.)
In Morris's search, he sought answers to three questions:
- What proportion of the total code on Hackage uses overlapping instances?
- In code that uses overlapping instances, how many instances overlap each other?
- Are there common patterns among the uses of overlapping instances?
Morris and his team used what they learned from this study to design the class system for their new language. They found that their language did not need to provide the full power of overlapping instances in order to support what programmers were really doing. Instead, they developed a new idea they call "instance chains" that was sufficient to support a large majority of the uses of overlapping instances. They are confident that their design can satisfy programmers because the design decision reflects actual uses of the concept in an extensive corpus of programs.
I love this kind of empirical research. One of the greatest assets the web gives us is access to large corpora of code: SourceForge and GitHub are examples large public repositories, and there are an amazing number of smaller domain-specific repositories such as Hackage and RubyGems. Why design languages or programming tools blindly when we can see how real programmers work through the code they write?
The more general notion of designing languages via observing behavior, forming theories, and trying them out is not new. In particular, I recommend the classic 1981 paper Design Principles Behind Smalltalk. Dan Ingalls describes the method by which the Smalltalk team grew its language and system as explicitly paralleling the scientific method. Morris's paper talks about a similar method, only with the observation phase grounded in an online corpus of code.
Not everyone in computer science -- or outside CS -- thinks of this method as science. Just this weekend Dirk Riehle blogged about the need to broaden the idea of science in CS. In particular, he encourages us to include exploration as a part of our scientific method, as it provides a valuable way for us to form the theories that we will test using the sort of experiments that everyone recognizes as science.
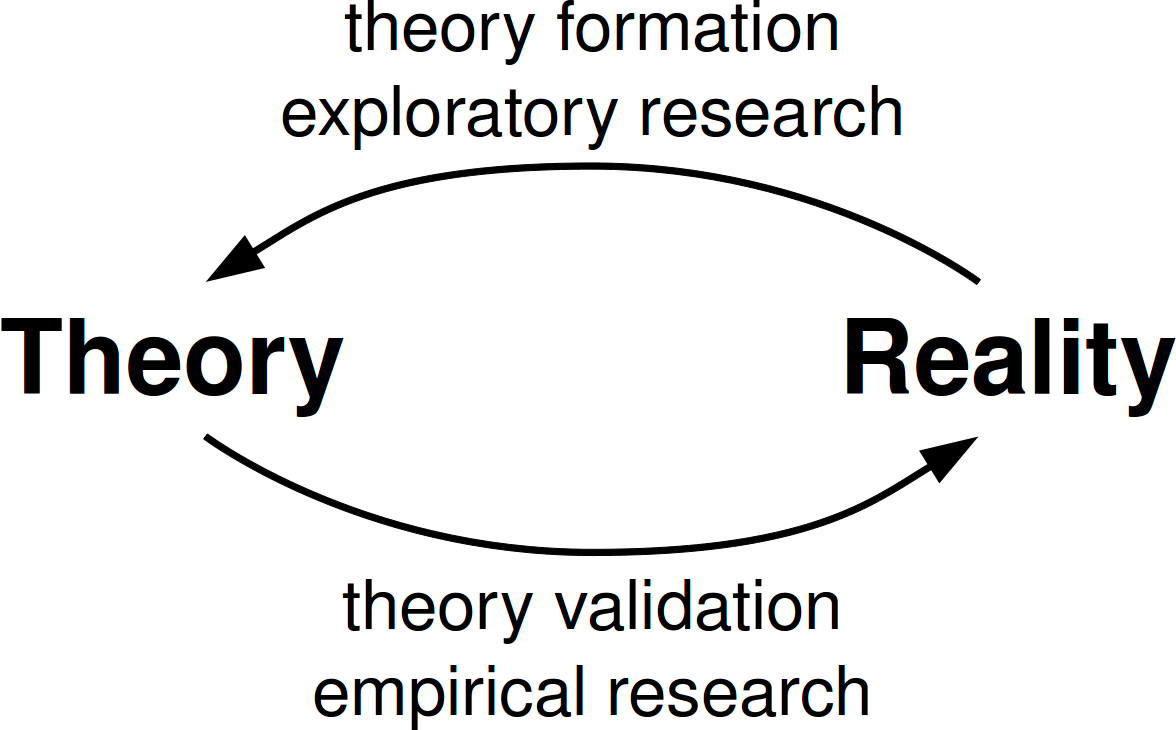
Unfortunately, too many people in computer science do not take this broad view. Note that Morris published his paper as an experience report at a symposium. He would have a hard time trying to get an academic conference program committee to take such a paper in its research track, without first dressing it up in the garb of "real" research.
As I mentioned in an earlier blog entry, one of my grad students, Nate Labelle, did an M.S. thesis a few years ago based on information gathered from the study of a large corpus of programs. Nate was interested in dependencies among open-source software packages, so he mapped the network of relationships within several different versions of Linux and within a few smaller software packages. This was the raw data he used to analyze the mathematical properties of the dependencies.
In that project, we trolled repositories looking for structural information about the code they contained. Morris's work studied Hackage to learn about the semantic content of the programs. While on sabbatical several years ago, I started a much smaller project of this sort to look for design patterns in functional programs. That project was sidetracked by some other questions I ran across, but I've always wanted to get back to it. I think there is a lot we could learn about functional programming in this way that would help us to teach a new generation of programmers in industry.
October 02, 2010 9:38 PM
Your Voice Cannot Command
I've been carrying this tune in my mind for the last couple of days, courtesy of singer-songwriter and fellow Indianapolis native John Hiatt:
So whatever your hands find to do
You must do with all your heart
There are thoughts enough
To blow men's minds and tear great worlds apart
...
Don't ask what you are not doing
Because your voice cannot command
In time we will move mountains
And it will come through your hands
One of my deepest hopes as a parent is that I can help my daughters carry this message with them throughout their lives.
I also figure I'll be doing all right as a teacher if my students take this message with them when they graduate, whether or not they remember anything particular about design patterns or lambda.
October 01, 2010 3:00 PM
Theory and Practice in Education Classrooms
The Fordham Institute has just published Cracks in the Ivory Tower?, a national survey of K-12 education professors. The publication page summarizes one finding that points out a gap between what happens in education courses and what many of us might think happens there:
The [education] professors see themselves as philosophers and evangelists, not as master craftsmen sharing tradecraft with apprentices and journeymen.
I have seen this gap in my own university's College of Education, with many of its required courses not adding much to the daily practice of teaching. Unfortunately, I've seen another gap in the tension between programs focused on teacher training, like the one at my school, and theoretical research-driven education programs at our R-1 sister schools. Many of the professors at those schools view what is taught at our school as too applied!
Most of us in computer science who are looking to help K-12 teachers use ideas from CS in their courses tend to be focused on helping teachers in the trenches. There isn't much value in us teaching, say, high school teaches a bunch of CS theory that is disconnected from what they do in their classrooms. They already have so much to teach and test that there really isn't room for a bunch of new content, and besides, most of them aren't all that interested in CS theory for its own sake. (That's true of many CS people themselves, of course.)
With help from Google this summer, my department offered CS4HS Iowa 2010, to introduce computing to K-12 science and math teachers using simulations in Scratch. The course looked at some CS ideas at the abstract level, but the meat of the course was practical techniques, both technical and pedagogical. Our hope was that an 8th grade math teacher or an 11th grade science teacher might be able to use computing to help them teach their own courses more effectively.
Mark Guzdial responds to the Fordham Institute report with several thoughtful observations. I certainly agree with this caution:
On the other hand, I don't share the sense in the report that if we "fixed" teacher education, we would "fix" teachers. I learned when I was an Education graduate student that pre-service teacher education is amazingly hard to fix.
I learned this only in the last few years, by participating in statewide meetings aimed at improving the state of STEM education in Iowa. The number and diversity of stakeholders at the table is often overwhelming, almost ensuring that little or no practical change will occur. Even when you narrow the conversation to professors at all the universities who teach teachers, you run into gaps of the sort highlighted in the report quote above. Even when you narrow the conversation even further to professors at a single university, there can be big gaps between what education professors want to do, what STEM professors think is important, and what the state Department of Education requires.
Guzdial again:
Education professors seek to avoid being merely "vocational instructors," so they emphasize being "change agents" (a term from the report) rather than focusing on developing the tradecraft of teaching. Doesn't this sound a lot like the tensions in computing education?
Yes, indeed. In a field like CS, students need to learn both theory and application if they hope to find ways to use their knowledge upon graduation and be able to stay relevant as the discipline changes over the course of their careers. But there are many challenges to face in trying to meet this two-headed goal. Four (or five) years is a short time. The foundational knowledge that CS faculty has tends to stay the same as the applications of that knowledge change the world, which over time makes it harder for faculty to keep up and not settle down. Without periodic immersion in applied tasks, how can a prof know the patterns of software their students need to know tomorrow?
Education professors face many of the same challenges in their own context. My wife has long argued to me that both CS professors and education professors should be required regularly to work in the trenches, whether that is developing software or teaching a bunch of unruly 7th-grade science students, to keep them grounded in the world outside the university. When I think about the challenge facing graduates of our Colleges of Education, I often wish that more of their education would be devoted to studying their craft at the feet of masters, spending their four years in college moving from apprentice and journeyman and finally to master themselves. They should be learning the patterns of learning and teaching that will help them progress along that path. Building a few courses around something like the pedagogical patterns project would be a great start.
I think you could apply the last three sentences of that paragraph to CS education and improve our outcomes as well.